不算非常难的题,但是对于没有app逆向经验的新人来说是挺好的上手题目
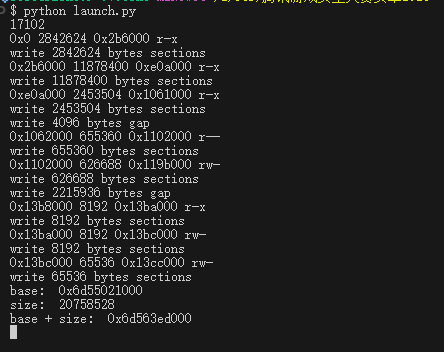
dump libli2cpp.so
进来先随便看看,unity题先看看c#的东西,il2cpp被加密过,ida里解析不出来,考虑运行时dump
直接用frida读,注意到对frida默认的端口做了检测,所以要转发到别的端口上

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
function dump(soName: string, timeout: number = 3000) {
setTimeout(() => {
let libSo = Process.getModuleByName(soName);
let base = libSo.base;
let size = libSo.size;
let sectionRanges = libSo.enumerateRanges("");
for (let i = 0; i < sectionRanges.length; i++) {
console.log(sectionRanges[i].base.sub(base), sectionRanges[i].size, sectionRanges[i].base.add(sectionRanges[i].size).sub(base), sectionRanges[i].protection);
Memory.protect(sectionRanges[i].base, sectionRanges[i].size, 'rwx');
let buffer = sectionRanges[i].base.readByteArray(sectionRanges[i].size);
console.log(`write ${sectionRanges[i].size} bytes sections`);
send(["dumpso", soName], buffer);
if (i + 1 < sectionRanges.length && sectionRanges[i].base.add(sectionRanges[i].size).compare(sectionRanges[i + 1].base) !== 0) {
let gap = Memory.alloc(sectionRanges[i + 1].base.sub(sectionRanges[i].base.add(sectionRanges[i].size)).toUInt32());
let buffer = gap.readByteArray(sectionRanges[i + 1].base.sub(sectionRanges[i].base.add(sectionRanges[i].size)).toUInt32());
console.log(`write ${sectionRanges[i + 1].base.sub(sectionRanges[i].base.add(sectionRanges[i].size)).toUInt32()} bytes gap`);
send(["dumpso", soName], buffer);
}
}
console.log("base: ", base);
console.log("size: ", size);
console.log("base + size: ", base.add(size));
}, timeout);
}
dump("libil2cpp.so");
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| import frida
import sys
import time
def handleResigerNatives(message):
print("----------------------------------------")
print("Native Method in class: {}".format(message['payload'][1]))
print("Native Method name: {}".format(message['payload'][2]))
print("Native Method signature: {}".format(message['payload'][3]))
print("Native Method address: {}".format(message['payload'][4]))
print("Which file register It: {}".format(message['payload'][5]))
def handleDumpSo(message, data):
with open("dump_"+message['payload'][1], "ab") as f:
f.write(data)
def onMessage(message, data):
if message['type'] == 'send':
if message['payload'][0] == "registerNatives":
handleResigerNatives(message)
elif message['payload'][0] == "dumpso":
handleDumpSo(message, data)
else:
print("[!!] Message from target: ", message['payload'])
else:
print("Not a send type Message", message['stack'])
with open('dumpso.js', "r", encoding="utf-8") as f:
jscode = f.read()
targetProcessPackName = "com.com.sec2023.rocketmouse.mouse"
device = frida.get_device_manager().add_remote_device("127.0.0.1:12345")
try:
pid = device.spawn(targetProcessPackName)
session = device.attach(pid)
print(pid)
except frida.ProcessNotFoundError:
print("No such process")
sys.exit(0)
script = session.create_script(jscode)
script.on('message', onMessage)
script.load()
device.resume(pid)
sys.stdin.read()
|
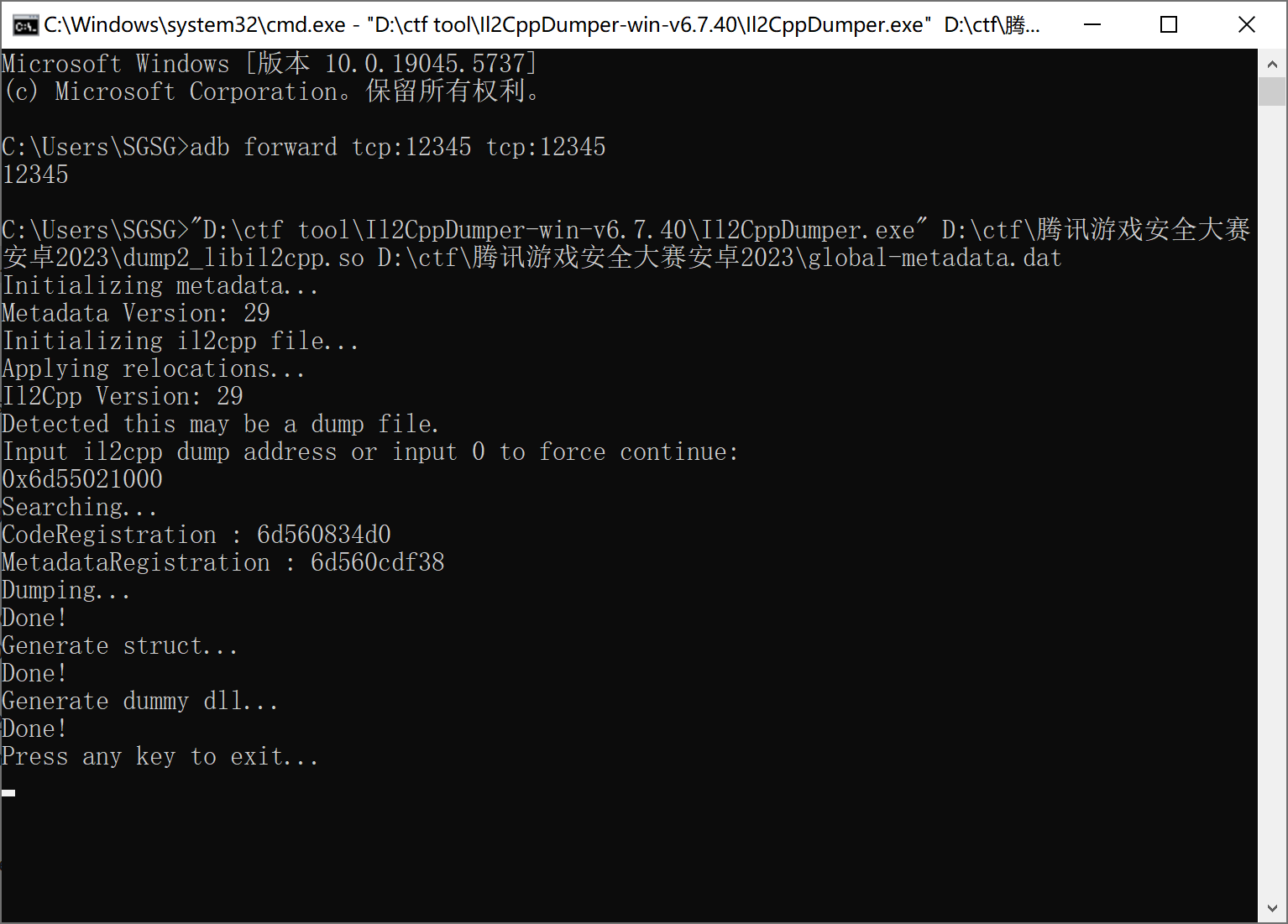
这样so基本都出来了,再结合ll2cppDumper和apk里找到的global-metadata修复一下c#符号信息
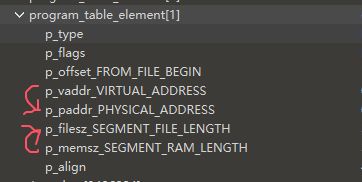
但是因为是dump的,所以偏移和节符号之类的多少有些损坏,这样直接扔进ida里是无法识别的,所以要修复elf,如果手动修的话就是把so扔进010里先跑一遍elf模板识别关键字段,然后把progame_table段里的物理地址值改成虚拟地址对应的值,把文件中的段大小改成内存中的段大小,具体原理就是因为dump下来的elf中数据的偏移都是还在内存中的偏移,同时因为内存中的elf会把一些像stack_segment之类只有在运行时才会占据实际空间的段拓展,所以有些段的位置会被挤歪,也就是物理地址和虚拟地址不符,而ida只识别物理地址,所以要把物理地址的值改成虚拟地址对应的值,还有把在文件中的大小改为在内存中的大小,这样才能定位真实的偏移
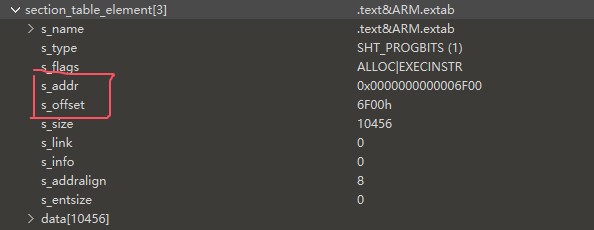
节表的部分在dump时都会损坏,要去未解密的so里把节表的部分复制过来
同理对节表(section_table)里的元素也做修正偏移的操作
注意到节表里有个储存各字段名称的部分由elf头里的string_table_index定位

这个值是节表的索引,对应的节表元素里储存了所有表头的名称,这个部分在dump的时候是会丢失的,手动修复就要去原来apk里的so中把对应的部分复制出来(因为表头名称是不加密的)
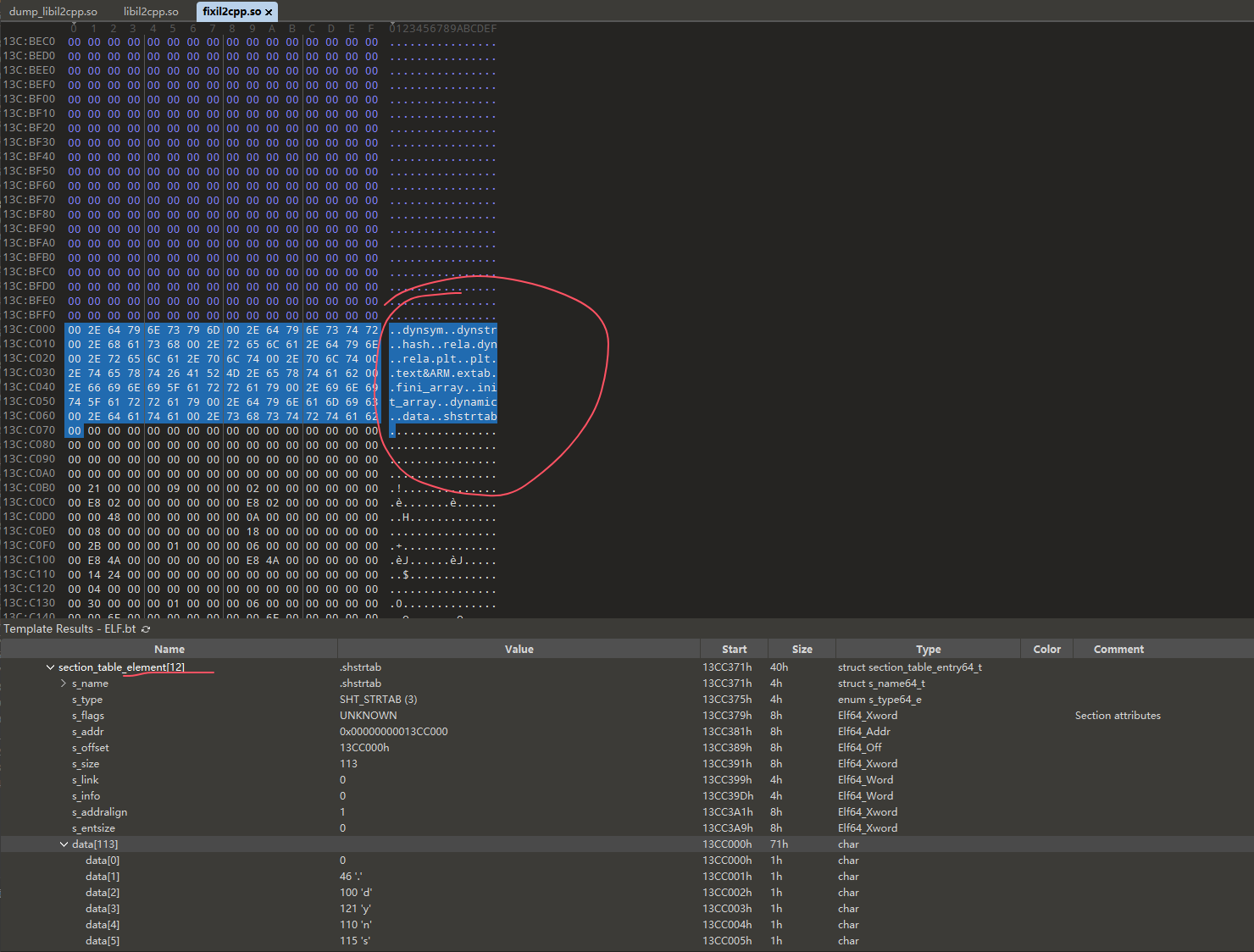
这些都修完后按理就修好了,修的过程中发现有些elf的部分没识别出来是正常情况,因为没修好010模板无法识别,边修边f5就会逐渐把符号表,节表之类的都显示出来
但是主播主播,你的操作太麻烦了,有没有一把梭的方法
有的有的,直接上soFixer,修之前记得先用ll2cpp dumper提取符号,然后在用soFixer修,不然修完后的ll2cpp dumper就不识别符号了,用soFixer只要输入dump时的基址就能一键修正偏移了
修完后就是用ll2cppdumper自带的ida脚本把符号信息导入ida,在ida的script file里选择ida_with_struct_py3.py这个脚本,然后按照提示依次选择script.json和il2cpp.h两个文件导入脚本,就可以在ida里恢复符号
记得ida里也要设定基址,在edit->segment->rebase一栏中填入dump时的基址
这样跑完后该有的符号就都有了,因为题目要求做注册机,token是用小键盘输入的,所以先搜下keyboard试试看能不能找到相关函数
分析注册机输入
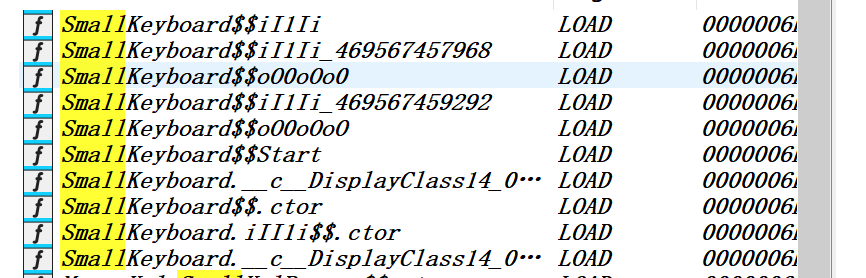
可以看到还是找到了,拿frida hook一下看看调用
这里虽然做的时候软件一直崩溃,但还是拿到了hook数据

这里是按了一下1按了一下enter,可以看到最后都调用了SmallKeyboard__iI1Ii,看看这个函数什么情况

可以看到这里针对keyType的三种不同情况做不同处理,其中type=2的情况又调用了别的函数,所以重点hook SmallKeyboard__iI1Ii_469567457968看看这个v23是什么,怀疑是我们的输入

hook结果如下,这个0x7b就是我们输入的123,点进这个函数看,发现最终调用了一个导入函数,如果跳过去是jumpout就手动c一下把数据转成代码,可能是ida误判没有把代码反编译出来

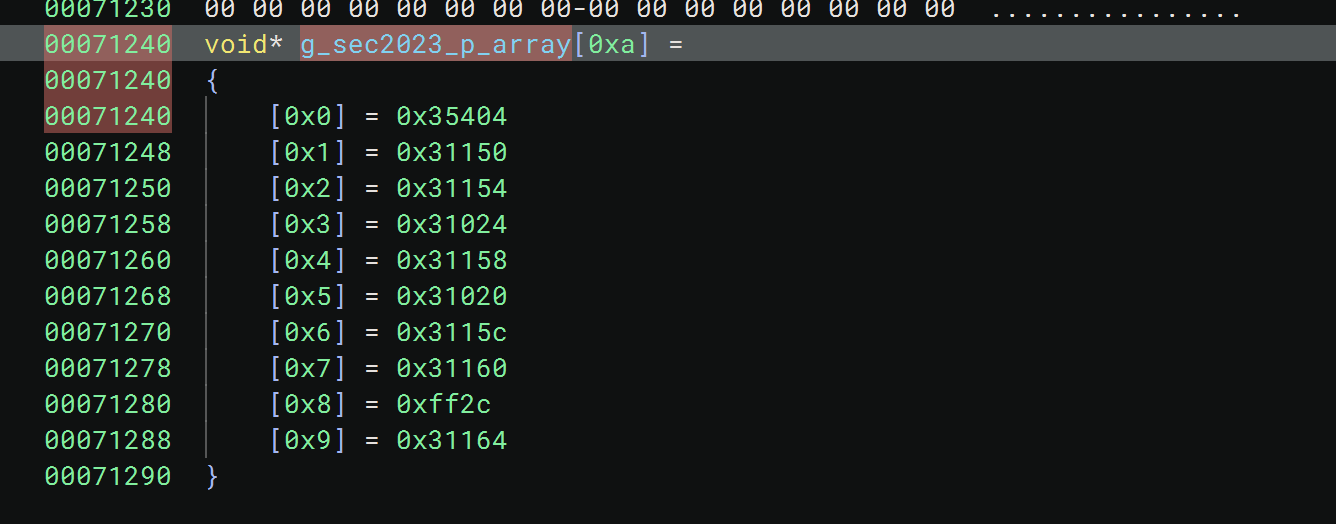
那么这里很有可能是加密了,我们得跳到sec2023这个so的导出表里找这个函数,这里指的是导出表的第十个元素
上文的hook脚本如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| setTimeout(() => {
let lib = Process.getModuleByName("libil2cpp.so");
console.log(lib.base);
let offset = 0x6EF9C28000;
let addr = [0x0000006EFA08E300,
0x0000006EFA08E18C,
0x0000006EFA08D880,
0x0000006EFA08DAB0,
0x0000006EFA08DFDC,
0x0000006EFA08DE90,
0x0000006EFA08E184,
0x0000006EFA08E2F8,
0x0000006EFA08E3B0,
0x0000006EFA08E3A8
]
var name = ["SmallKeyboard___ctor(SmallKeyboard_o *this, const MethodInfo *method)",
"SmallKeyboard__Start(SmallKeyboard_o *this, const MethodInfo *method)",
"void SmallKeyboard__iI1Ii(SmallKeyboard_o *this, SmallKeyboard_iII1i_o *info, const MethodInfo *method)",
"SmallKeyboard__iI1Ii_469567457968(SmallKeyboard_o *this, uint64_t i1I, const MethodInfo *method)",
"void SmallKeyboard__iI1Ii_476641288156(SmallKeyboard_o *this, UnityEngine_GameObject_o *go, const MethodInfo *method",
"SmallKeyboard__oO0oOo0(SmallKeyboard_o *this, const MethodInfo *method)",
"SmallKeyboard__oO0oOoO(SmallKeyboard_o *this, const MethodInfo *method)",
"SmallKeyboard___c__DisplayClass14_0___ctor(SmallKeyboard___c__DisplayClass14_0_o *this, const MethodInfo *method)",
"SmallKeyboard___c__DisplayClass14_0___Start_b__0(SmallKeyboard___c__DisplayClass14_0_o *this, const MethodInfo *method)",
"SmallKeyboard_iII1i___ctor(SmallKeyboard_iII1i_o *this, const MethodInfo *method)"
]
for (let i = 0; i < addr.length; i++) {
console.log("hook " + name[i]);
Interceptor.attach(lib.base.add(addr[i]).sub(offset), {
onEnter: function () {
console.log("called " + name[i]);
}
})
}
Interceptor.attach(lib.base.add(0x0000006EFA4839C4).sub(offset), {
onLeave(retval) {
console.log(retval);
},
})
}, 3000);
|
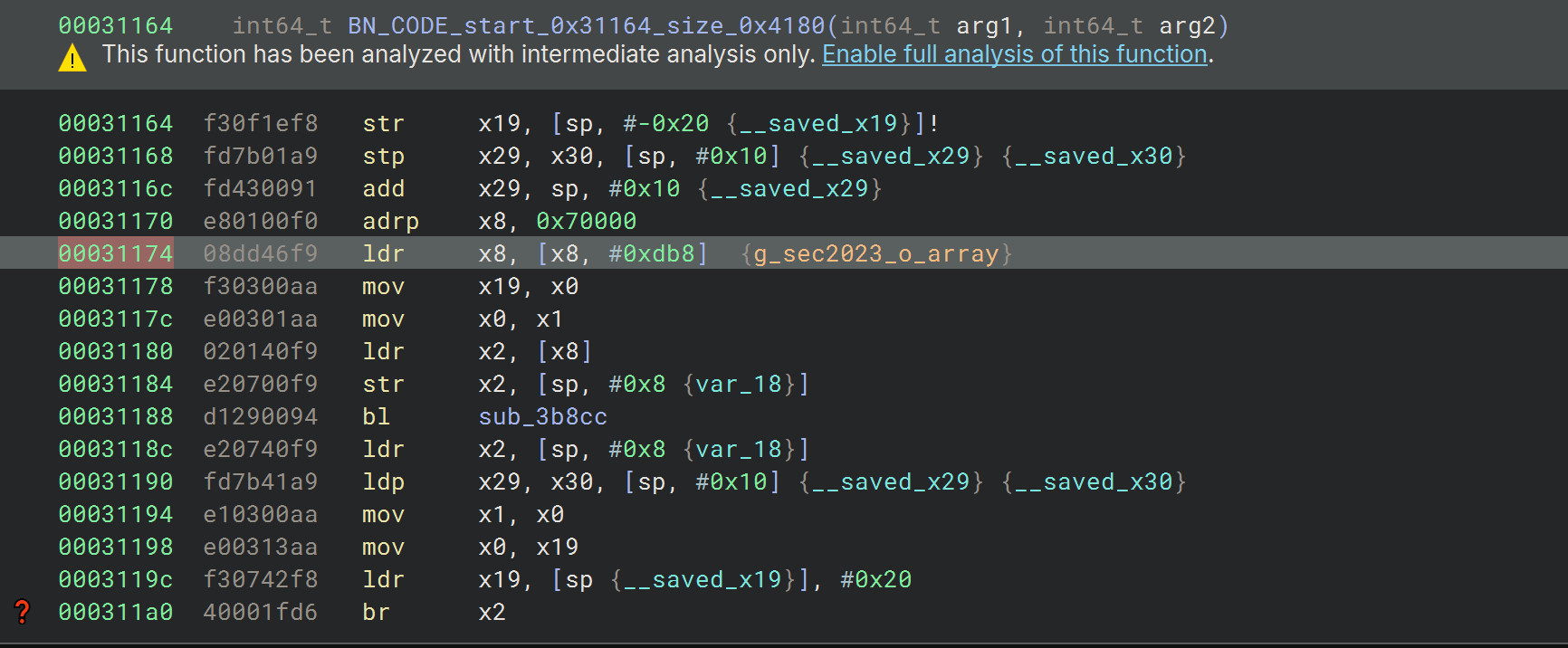
这里有间接跳转,可以把so的data段改成只读,这样bn会自动计算部分跳转地址,当然还是不怎么可看,最好结合trace分析控制流
CRC校验绕过
我们hook sub_3b8cc这个函数时会发现app会跳出,可能是crc校验检测到了inline hook,去hook open,openat等都没有发现相关调用,感觉可能是使用svc来避免相关函数被frida hook,使用stackplz对内核跟踪后发现调用了openat

这个时候根据调用栈去找检测的位置,基本上每个调用下面都紧跟一个cmp,我们hook 参数看看是否像是在判断检测的最终结果,不断排查可以往前跳到sub_353e0这个函数
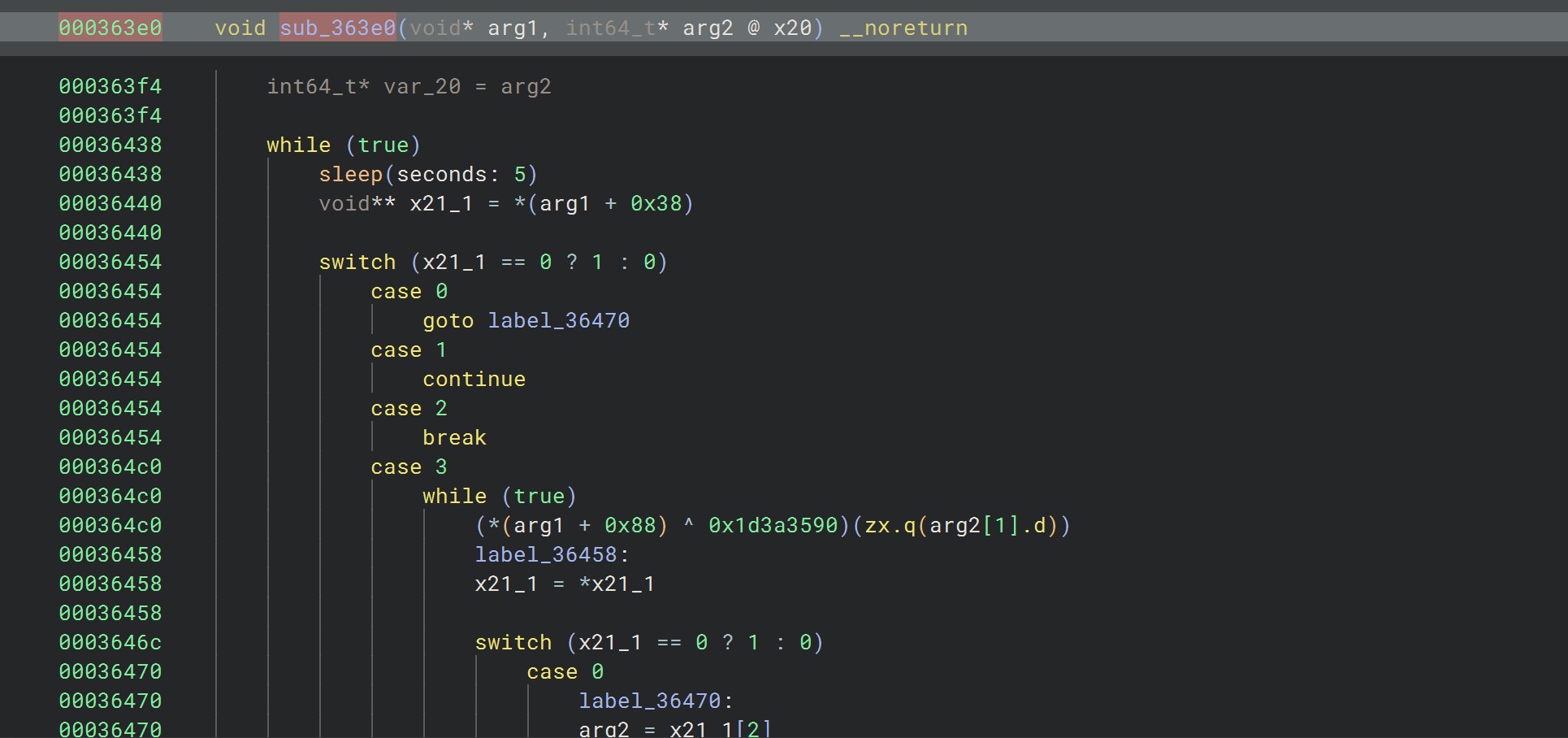
可以看到这个sleep其实就已经很说明问题了,因为app不是马上跳出,而是过一会再跳出的
这个时候我们把0x3649c这个位置的w0给hook成0,app就不跳出了,说明找对位置了,继续分析加密
加密1
第一处加密的参数是输入的高32位,点进去看看像是对每个字节分别做了两次计算
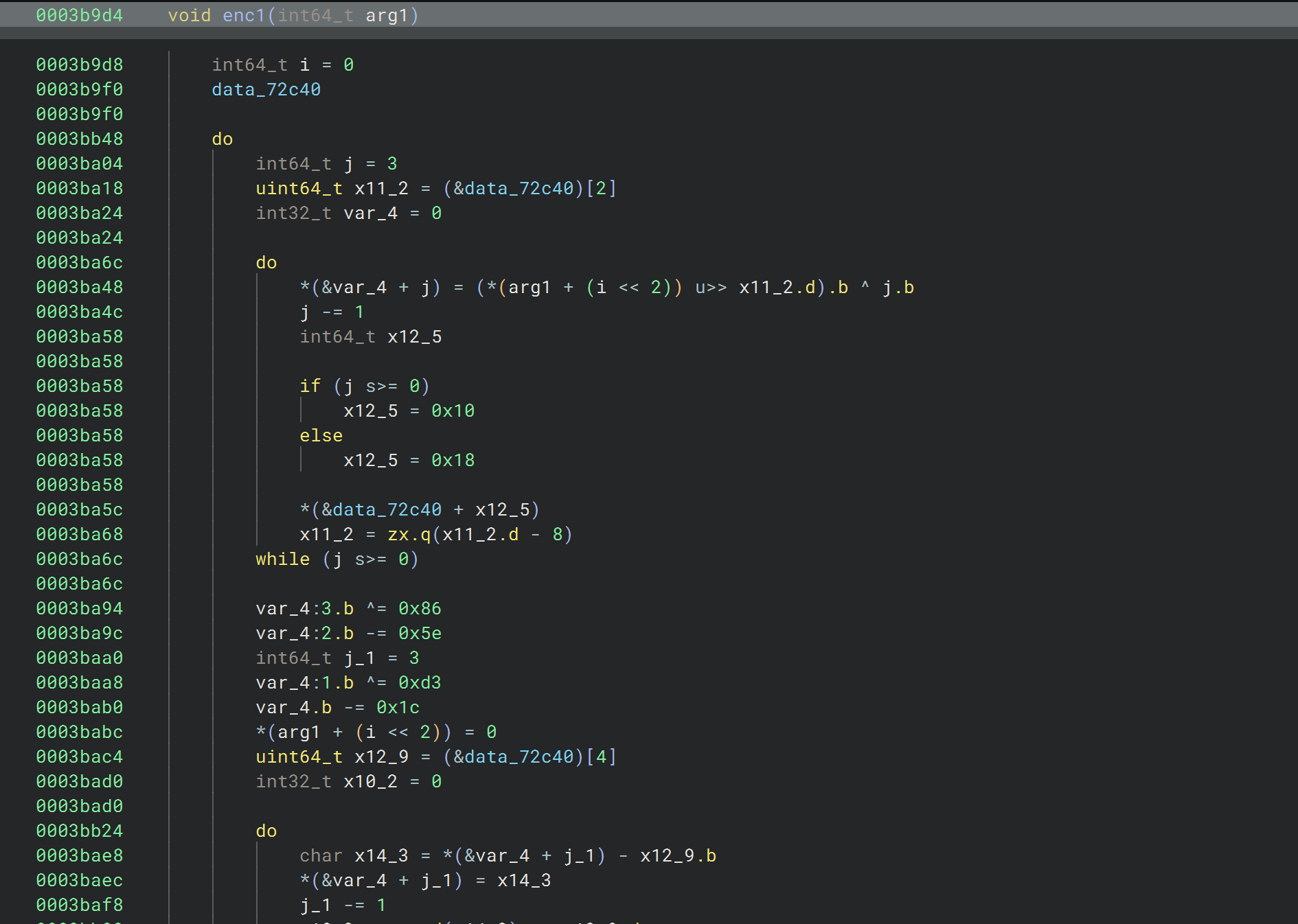
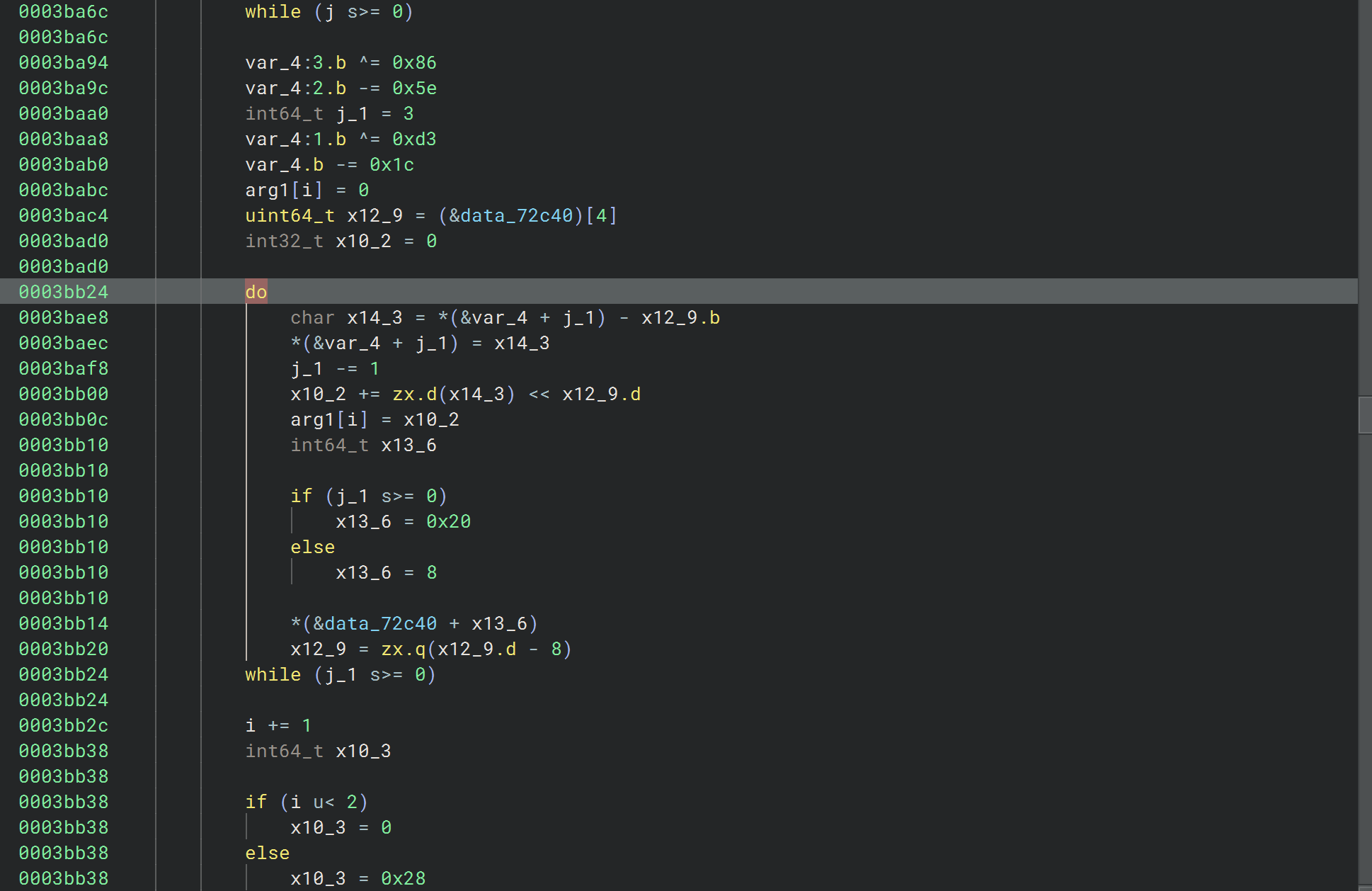
可以hook下验证下想法
就是些计算,hook下看下具体计算流程,然后就可以写解密了
1
2
3
4
5
6
7
8
9
10
11
|
enc = [0x89, 0x22, 0x6d, 0x17]
enc[0] = enc[0]+0x1c
enc[1] = (enc[1]+8) ^ 0xd3 ^ 1
enc[2] = ((enc[2]+16)+0x5e) ^ 2
enc[3] = (enc[3]+24) ^ 0x86 ^ 3
for i in range(0, 4):
print(hex(enc[i] & 0xFF))
|
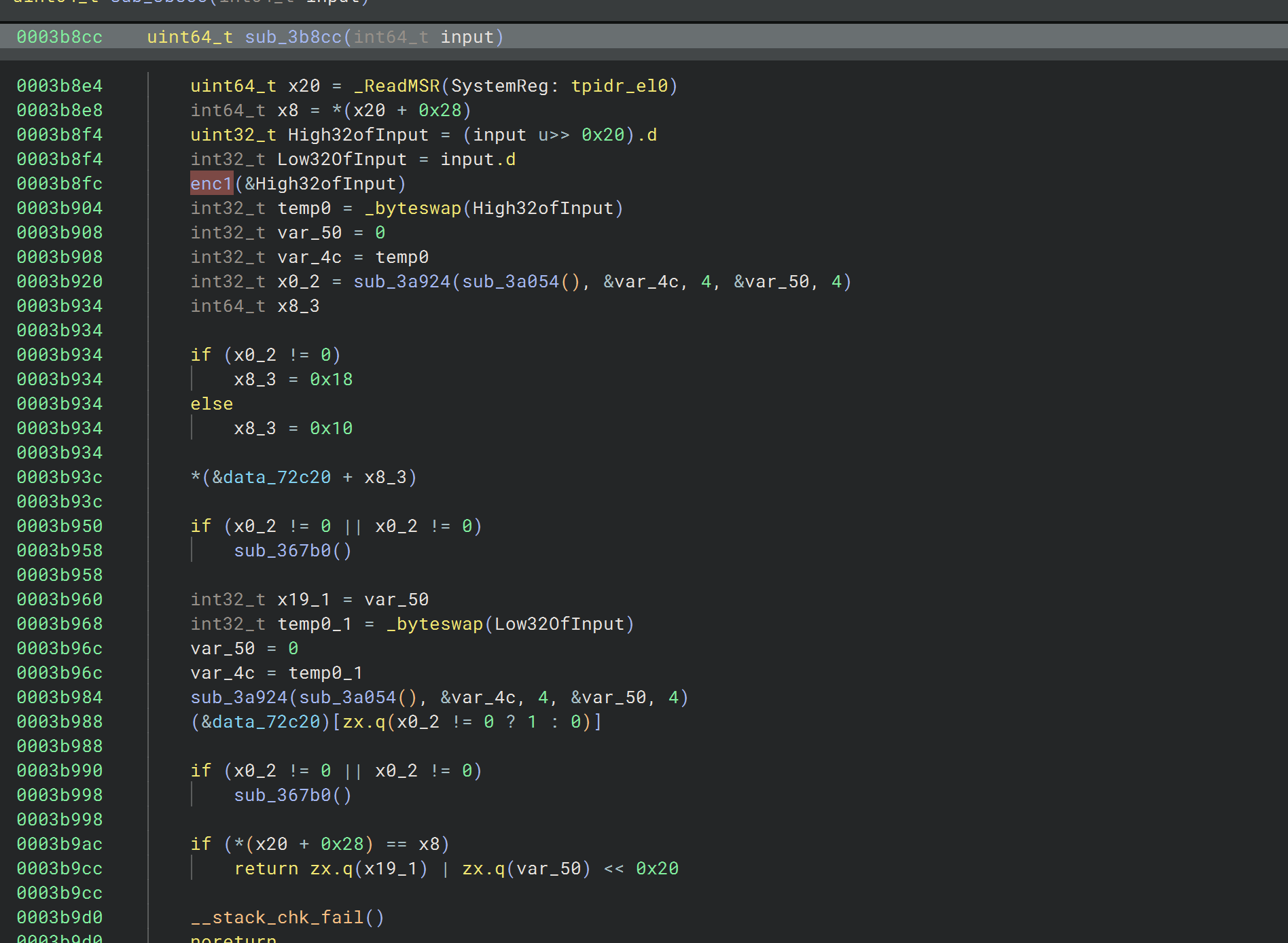
然后是一个byteswap宏,就是把加密完的部分的字节序反过来
加密2
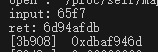
在下面是sub_3a924是调用native调用dex加密,hook GetStaticMethodID这个函数去找加密函数在dex中的位置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
function hookJNIgetStaticMethodID() {
console.log("hook JNIgetStaticMethodID");
let symbols = Module.load("libart.so").enumerateSymbols();
for (let i = 0; i < symbols.length; i++) {
let symbol = symbols[i];
if (symbol.name.indexOf("art") >= 0 &&
symbol.name.indexOf("JNI") >= 0 &&
symbol.name.indexOf("GetStaticMethodID") >= 0 &&
symbol.name.indexOf("CheckJNI") < 0) {
console.log(symbol.name);
Interceptor.attach(symbol.address, {
onEnter: function (args) {
var Name = args[2].readUtf8String();
var sig = args[3].readUtf8String();
let whoCallIt = DebugSymbol.fromAddress(this.returnAddress).toString();
send(["getStaticMethodID", Name, sig, whoCallIt]);
}
})
}
}
}
setTimeout(hookJNIgetStaticMethodID, 3000);
|
用frida-dexdump把dex dump下来,然后可以都扔进jeb里了,加密部分加了平坦化混淆,jeb效果好一点

就是循环右移后进行异或和加法,可以写解密了
1
2
3
4
5
6
7
8
9
10
11
12
13
| key = [50, -51, -1, -104, 25, -78, 0x7C, -102]
b1 = [0xf8, 0xd0, 0x17, 0x96]
b1 = list(reversed(b1))
for i in range(0, 4):
b1[i] = (b1[i]-i) & 0xFF
b1[i] = (b1[i] ^ key[i]) & 0xFF
v = (b1[0] << 24) | (b1[1] << 16) | (b1[2] << 8) | b1[3]
v = v & 0xFFFFFFFF
v1 = ((v << 7) | (v >> 25)) & 0xFFFFFFFF
print(hex(v1))
|
低32位
注意虽然反编译没有直接显示低32位被扔进了enc1里,但其实低32位也经历了一次enc1,应该是类型识别导致的问题
然后是把低32位字节序反过来,再一样扔进那个dexcall里
最后是把高32位放在低位,低32位放在高位拼起来返回
跨文件跳转

看到这里还根据一个全局导出变量做了跳转,但是静态不好算这个变量,hook一下看看位置
1
2
3
4
5
| Interceptor.attach(lib.base.add(0x311a0), {
onEnter: function () {
console.log(DebugSymbol.fromAddress(this.context.x2));
}
})
|

跳回libil2cpp了,和基址算一下偏移再去找跳到哪了

再跳过去
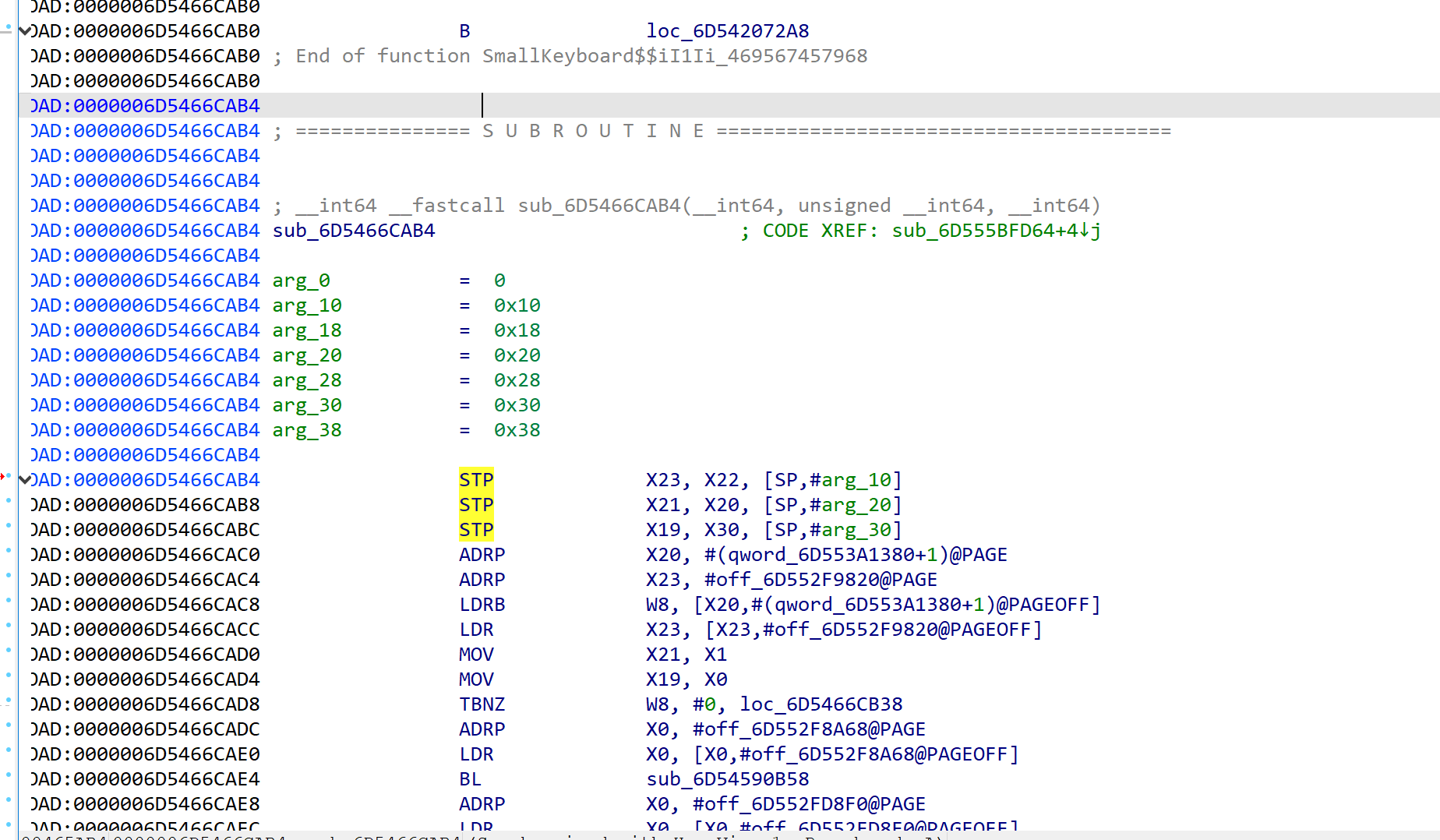
发现其实就是之前跳到sec2023.so的加密的下面
也就是说加密完的64位数被弄到这个函数里处理了
il2cpp中的加密
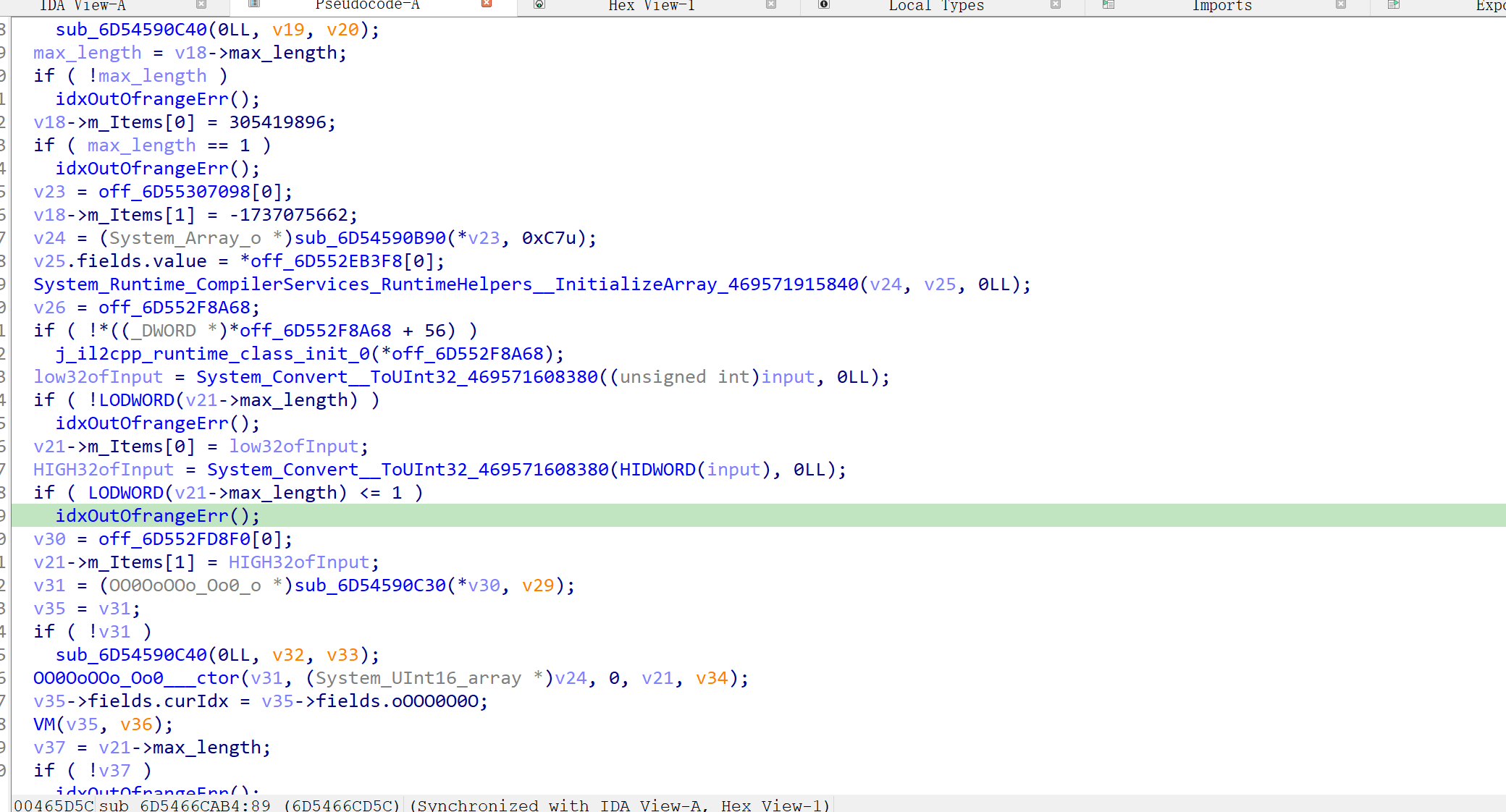
前面搞了一大坨初始化,传入输入也被分为高低各两份放进了v21这个结构体里,跟踪这个结构体,最后是走到了一个vm加密里,至于为什么断定这是vm因为里面进去就是一个大while(1),而且看着也不像其他加密
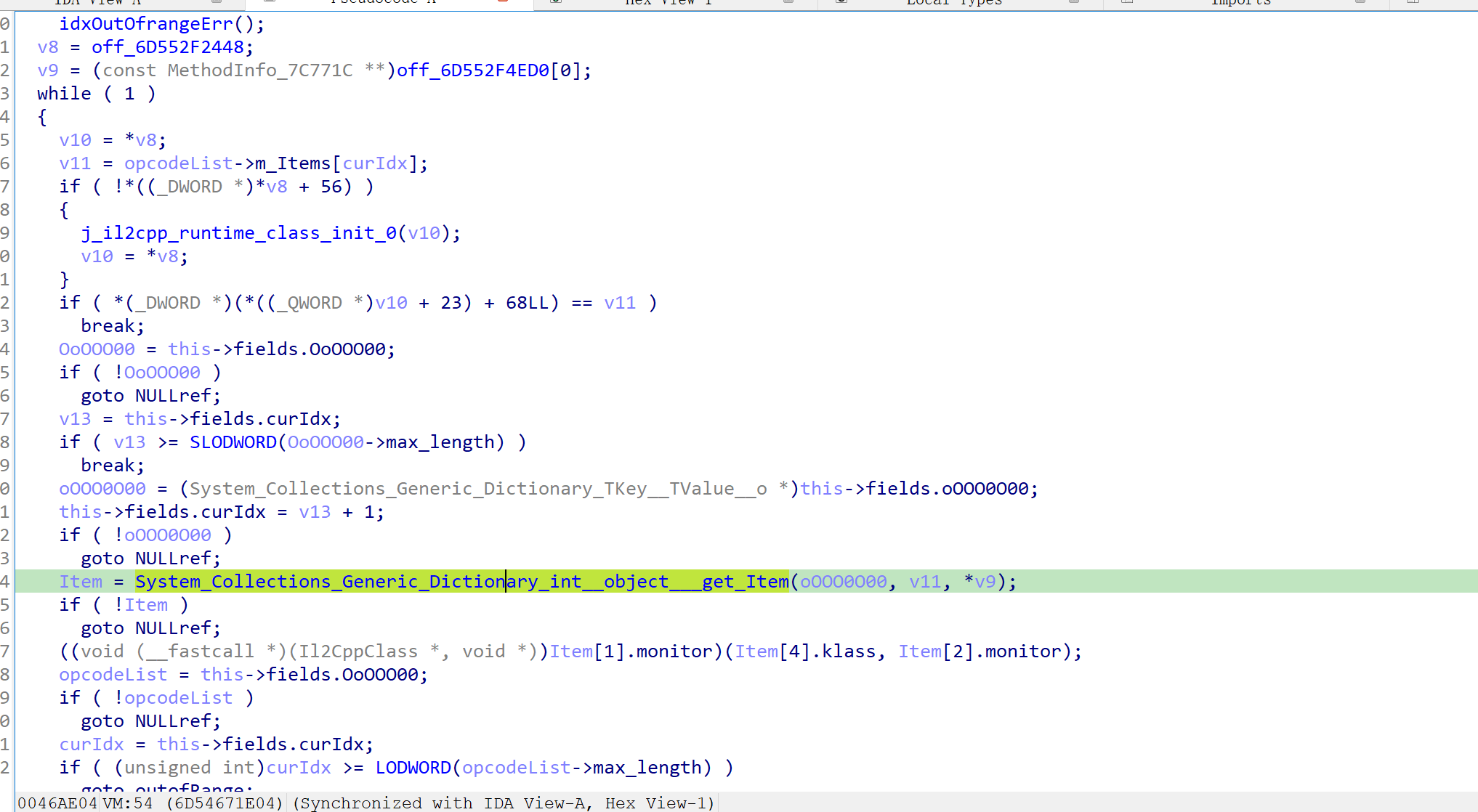
vm里面这一大坨重点关注那个get_Item的库函数,hook他的第二个参数看看下标都是什么
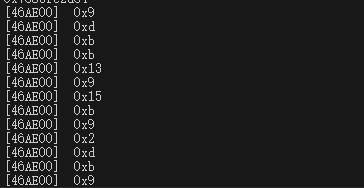
看到种类不多,接下来该去找handle的实现了
1
2
3
4
5
6
| Interceptor.attach(ll2.base.add(0x46AE1C), {
onEnter: function () {
console.log("[handle]", ptr(this.context.x9).sub(ll2.base).add(0x6D54207000))
}
})
|
这里简单trace下拿下handle的函数地址
vm分析
handle里面有些和数值计算相关的地方用了mba算式混淆,ida9.0内置了解mba混淆的插件

拿完handle后一个个写trace,把指令和参数拿下来
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
| function main() {
var ll2 = Process.getModuleByName("libil2cpp.so");
var idabase = 0x6D54207000;
var basePtr = ll2.base.sub(idabase);
Interceptor.attach(basePtr.add(0x6D5466CBD0), {
onEnter() {
console.log("low32 of input: ", this.context.x0);
}
})
Interceptor.attach(basePtr.add(0x6D5466CBF4), {
onEnter() {
console.log("hig32 of input: ", this.context.x0);
}
})
Interceptor.attach(basePtr.add(0x6D5466CC3C), {
onEnter() {
console.log("ret: ", this.context.x21, this.context.x22);
}
})
Interceptor.attach(basePtr.add(0x6D546725CC), {
onEnter() {
console.log(`stack[${this.context.x10}] = ${this.context.x8}`);
}
})
var heapIdx = 0, stackIdx = 0;
Interceptor.attach(basePtr.add(0x6D54672548), {
onEnter() {
stackIdx = this.context.x9;
heapIdx = this.context.x8;
let value = ptr(this.context.x10).add(this.context.x9 * 4 + 0x20).readU32();
console.log(`heap[${heapIdx}] = stack[${stackIdx}] // stack[${stackIdx}] = ${value}`)
}
})
Interceptor.attach(basePtr.add(0x6D54672438), {
onEnter() {
heapIdx = this.context.x8;
}
})
Interceptor.attach(basePtr.add(0x6D54672460), {
onEnter() {
stackIdx = this.context.x10;
console.log(`stack[${stackIdx}] = heap[${heapIdx}] // heap[${heapIdx}] = ${this.context.x8}`)
}
})
Interceptor.attach(basePtr.add(0x6D54672088), {
onEnter() {
console.log(`push ${this.context.x10} >> ${this.context.x11} to stack // ${this.context.x10 >> this.context.x11}`)
}
})
Interceptor.attach(basePtr.add(0x6D54672104), {
onEnter() {
console.log(`push ${this.context.x10} & ${this.context.x11} to stack // ${this.context.x10 & this.context.x11}`)
}
})
Interceptor.attach(basePtr.add(0x6D54671F14), {
onEnter() {
console.log(`push ${this.context.x10} - ${this.context.x11} to stack // ${this.context.x10 - this.context.x11}`)
}
})
Interceptor.attach(basePtr.add(0x6D5467220C), {
onEnter() {
console.log(`push ${this.context.x10} < ${this.context.x11} to stack // ${this.context.x10 < this.context.x11}`)
}
})
Interceptor.attach(basePtr.add(0x6D54672180), {
onEnter() {
console.log(`push ${this.context.x10} ^ ${this.context.x12} to stack // ${this.context.x10 ^ this.context.x12}`)
}
})
Interceptor.attach(basePtr.add(0x6D546723D8), {
onEnter() {
heapIdx = this.context.x10;
let value = ptr(this.context.x11).add(this.context.x10 * 4 + 0x20).readU32();
console.log(`load heap[${heapIdx}] to stack // heap[${heapIdx}] = ${value}`)
}
})
Interceptor.attach(basePtr.add(0x6D54672008), {
onEnter() {
console.log(`push ${this.context.x10} << ${this.context.x11} to stack // ${this.context.x10 << this.context.x11}`)
}
})
Interceptor.attach(basePtr.add(0x6D54671E98), {
onEnter() {
console.log(`push ${this.context.x10} + ${this.context.x11} to stack // ${this.context.x10 + this.context.x11}`)
}
})
Interceptor.attach(basePtr.add(0x6D5467232C), {
onEnter() {
console.log("jmp if zero");
}
})
Interceptor.attach(basePtr.add(0x6D546722C4), {
onEnter() {
console.log("jmp if not zero");
}
})
}
setTimeout(main, 1000);
|
这里注意有有几条指令(比如load i32 to stack) 执行操作的位置离ret非常近,如果frida inline hook的点选的不好会导致程序直接崩溃,因为注入点没有足够的空间容纳跳转指令
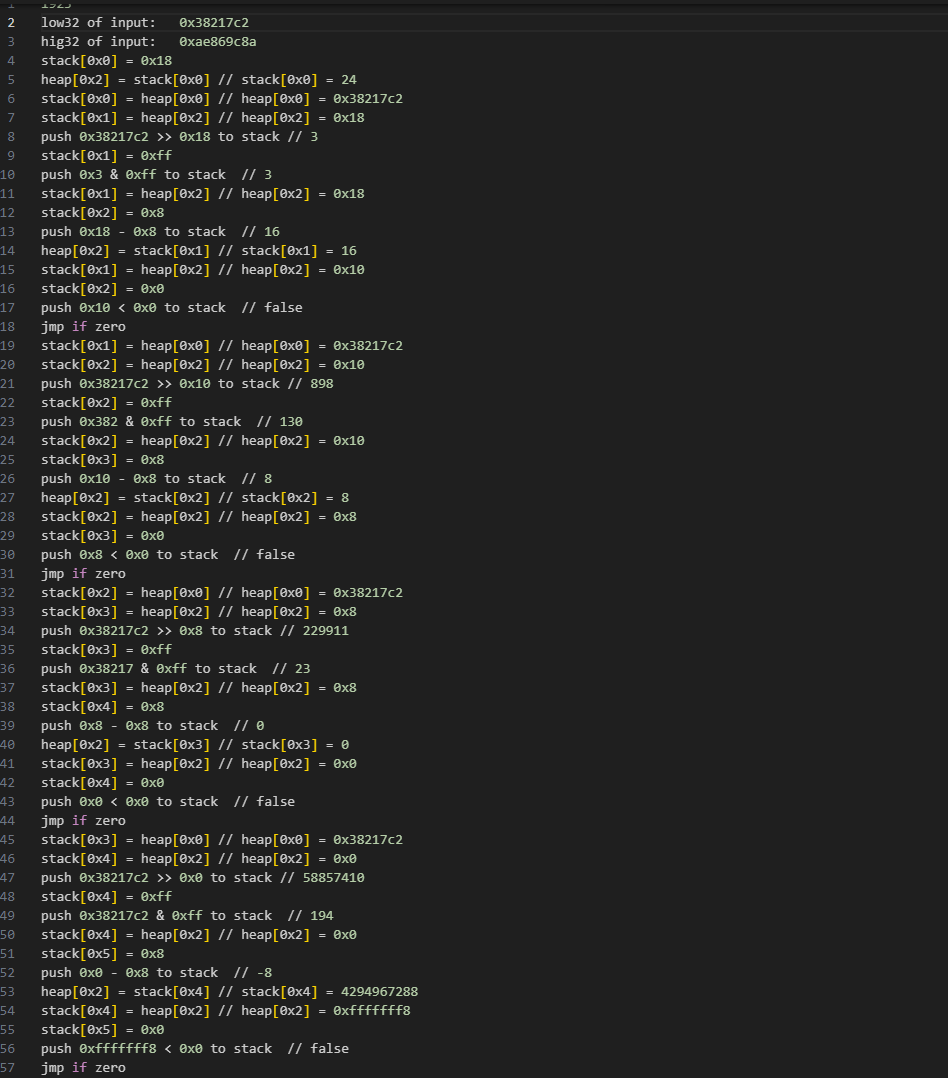
trace完大概长这样,大约350条
然后就可以手撕了,能复原出来加密算法如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| low32 = 0x038217c2
hig32 = 0xae869c8a
a1 = [0, 0, 0, 0]
for i in range(24, -1, -8):
a1[i//8] = (low32 >> i) & 0xff
a2 = [0, 0, 0, 0]
a2[0] = a1[0]-0x1b
a2[1] = a1[1] ^ 0xc2
a2[2] = a1[2]+0xa8
a2[3] = a2[3] ^ 0x36
res1 = 0
for i in range(0, 25, 8):
res1 |= (((a2[i//8] ^ i) & 0xFF) << i)
a3 = [0, 0, 0, 0]
for i in range(24, -1, -8):
a3[i//8] = (hig32 >> i) & 0xff
a4 = [0, 0, 0, 0]
a4[0] = a3[0]-0x2f
a4[1] = a3[1] ^ 0xb6
a4[2] = a3[2]+0x37
a4[3] = a3[3] ^ 0x98
res2 = 0
for i in range(0, 25, 8):
res2 |= (((a4[i//8] + i) & 0xFF) << i)
|
然后解密如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| def decodeVM(ret1, ret2):
a1 = [0, 0, 0, 0]
a2 = [0, 0, 0, 0]
a3 = [0, 0, 0, 0]
a4 = [0, 0, 0, 0]
for i in range(0, 25, 8):
a4[i//8] = (ret2 >> i) & 0xff
a4[i//8] = a4[i//8]-i
a3[0] = a4[0]+0x2f
a3[1] = a4[1] ^ 0xb6
a3[2] = a4[2]-0x37
a3[3] = a4[3] ^ 0x98
for i in range(0, 25, 8):
a2[i//8] = (ret1 >> i) & 0xff
a2[i//8] = a2[i//8] ^ i
a1[0] = a2[0]+0x1b
a1[1] = a2[1] ^ 0xc2
a1[2] = a2[2]-0xa8
a1[3] = a2[3] ^ 0x36
res1 = 0
res2 = 0
for i in range(0, 25, 8):
res1 |= (((a1[i//8] & 0xFF) << i))
res2 |= (((a3[i//8] & 0xFF) << i))
print("low", hex(res1))
print("hig", hex(res2))
return res1, res2
|
xtea
魔改了一个xtea,这个随便逆下就行了,xtea的解密没什么好说的,注意用了两个sum以及sum的初始值
key就动调拿一下就行
1
2
3
4
5
6
7
| Interceptor.attach(ll2.base.add(0x465C60), {
onEnter() {
for (let i = 0; i < 12; i++) {
console.log(`key[${i}]: `, this.context.x0.add(i * 4).readU32().toString(16));
}
}
})
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| void xteaDecrypt(uint32_t *v, uint32_t *k)
{
uint32_t sum = 0, v0 = v[0], v1 = v[1];
uint32_t sum1 = -1091584273;
uint32_t sum2 = -1650623010;
uint32_t delta = 559038737;
sum1 -= 64 * delta;
sum2 -= 64 * delta;
sum = delta * 32;
uint32_t ks2 = (sum2 >> 13) & 3;
for (int i = 0; i < 64; i++)
{
sum2 += delta;
v1 -= (sum2 + k[(sum2 >> 13) & 3]) ^ (((v0 << 8) ^ (v0 >> 7)) - v0);
sum1 += delta;
v0 -= (sum1 - k[sum1 & 3]) ^ (((v1 << 7) ^ (v1 >> 8)) + v1);
}
v[0] = v0;
v[1] = v1;
}
int main()
{
uint32_t key[4] = {0x7b777c63, 0xc56f6bf2, 0x2b670130, 0x76abd7fe};
uint32_t plaintext[2] = {71807475, 0};
xteaDecrypt((uint32_t *)plaintext, key);
printf("%08X %08X", plaintext[0], plaintext[1]);
return 0;
}
|
总结解密
输入转成64位整数先跳到libsec2023.so中分高低两份分别进行简单计算加密和字节翻转和dex中的混淆加密,然后高低两份调换位置重新拼成64位传入libil2cpp.so中传入一个vm算法中加密,然后结果再传入xtea中加密,加密完后高位部分和0比较,低位部分和token比较
把上面的解密拼一下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
| def decodeVM(ret1, ret2):
a1 = [0, 0, 0, 0]
a2 = [0, 0, 0, 0]
a3 = [0, 0, 0, 0]
a4 = [0, 0, 0, 0]
for i in range(0, 25, 8):
a4[i//8] = (ret2 >> i) & 0xff
a4[i//8] = a4[i//8]-i
a3[0] = a4[0]+0x2f
a3[1] = a4[1] ^ 0xb6
a3[2] = a4[2]-0x37
a3[3] = a4[3] ^ 0x98
for i in range(0, 25, 8):
a2[i//8] = (ret1 >> i) & 0xff
a2[i//8] = a2[i//8] ^ i
a1[0] = a2[0]+0x1b
a1[1] = a2[1] ^ 0xc2
a1[2] = a2[2]-0xa8
a1[3] = a2[3] ^ 0x36
res1 = 0
res2 = 0
for i in range(0, 25, 8):
res1 |= (((a1[i//8] & 0xFF) << i))
res2 |= (((a3[i//8] & 0xFF) << i))
print("low", hex(res1))
print("hig", hex(res2))
return res1, res2
def decode1(enc):
print(hex(enc))
enc = [(enc >> 24) & 0xFF, (enc >> 16) &
0xFF, (enc >> 8) & 0xFF, enc & 0xFF]
print(list(map(hex, enc)))
enc[0] = enc[0]+0x1c
enc[1] = (enc[1]+8) ^ 0xd3 ^ 1
enc[2] = ((enc[2]+16)+0x5e) ^ 2
enc[3] = (enc[3]+24) ^ 0x86 ^ 3
print(hex((enc[0] << 24) | (enc[1] << 16) | (enc[2] << 8) | enc[3]))
return (enc[0] << 24) | (enc[1] << 16) | (enc[2] << 8) | enc[3]
def decodeDex(enc):
key = [50, -51, -1, -104, 25, -78, 0x7C, -102]
b1 = [(enc >> 24) & 0xFF, (enc >> 16) &
0xFF, (enc >> 8) & 0xFF, enc & 0xFF]
print(enc)
print(list(map(hex, b1)))
b1 = list(reversed(b1))
for i in range(0, 4):
b1[i] = (b1[i]-i) & 0xFF
b1[i] = (b1[i] ^ key[i]) & 0xFF
v = (b1[0] << 24) | (b1[1] << 16) | (b1[2] << 8) | b1[3]
v = v & 0xFFFFFFFF
v1 = ((v << 7) | (v >> 25)) & 0xFFFFFFFF
print(hex(v1))
return v1
def byteswap(x):
return ((x & 0x000000FF) << 24) | ((x & 0x0000FF00) << 8) | ((x & 0x00FF0000) >> 8) | ((x & 0xFF000000) >> 24)
low32 = 0x7CD0D74B
hig32 = 0xEB77B65B
low32, hig32 = decodeVM(low32, hig32)
low32, hig32 = hig32, low32
low32 = decodeDex(low32)
low32 = byteswap(low32)
low32 = decode1(low32)
print("low32:", hex(low32))
hig32 = decodeDex(hig32)
hig32 = byteswap(hig32)
hig32 = decode1(hig32)
print("hig32:", hex(hig32))
print(hex((hig32 << 32) | low32))
print((byteswap(hig32) << 32) | byteswap(low32))
|
把xtea中解出来的部分分别扔进low32,hig32里,然后跑就行了