stalker别来沾边,我怕qbdi误会
汇编粒度trace唯一指定框架
什么是QBDI
QDBI全名QuarkslaB-Dynamic bianry Instrumentation,是一种基于DBI框架的细粒度trace框架,其运行原理和Frida Stalker类似,采用对目标程序的指令按基本块切分后JIT编译成插入了回调的代码,然后再在目标程序同一进程空间中执行
why QBDI
trace的方案有很多,但QBDI是这里面性能最好的,ebpf需要在用户态和内核态之间来回切换开销不可接受,而且还不支持windows,unidbg需要各种补环境,代码越写越臃肿,frida-stalker是这里面最接近qbdi方案的,但是stalker本身bug很多,而且性能不如qbdi,而QBDI不仅性能好,而且跨平台跨架构,支持C API和Python API,还有迁移到frida的js/ts API
frida/QBDI
frida/QBDI是qbdi的js API,在设计初就和frida联动,而且上手非常容易
VM
VM是qbdi中管理回调和代码执行的对象,这里介绍几个基本的方法
VM.addInstrumentedModuleFromAddr(addr)
这个函数将一个地址所在的整个内存段纳入VM的插桩范围,注意到qbdi的VM默认不对任何地址插桩,也就是说就算调用VM.call,也需要执行的地址处于插桩范围内才会触发回调,这个addr参数可以传number也可以传frida的NativePointer
VM.newInstCallback(cbk)
这个函数返回一个指令回调对象,也就是VM每执行一句指令就会触发一次的回调,cbk参数是一个签名为function(vm,gpr,fpr,data)的js函数,这里vm就是执行指令的vm对象,gpr是触发回调时的常规寄存器信息,fpr是浮点寄存器信息,data是创建回调时用户提供的额外数据,这个函数必须返回一个VMAction枚举量(continue,skip ....),否则会导致vm的执行出现不可预测的行为
VM.addCodeCB(pos, cbk, data, priority)
这个函数用于把一个回调绑定到VM对象,pos指的是要在指令执行前还是执行后触发该回调(有PreInst和PostInst)两个选项,cbk是回调对象,data则是传递给回调的数据,priority指的是这个回调的优先级,处于同一位置,数字越大的回调会越先触发
VM.addMemAccessCB(type, cbk, data, priority)
这个函数专门用来为任意位置的内存访问行为添加回调,type可以选择读,写或者读写都监测,cbk是指令回调对象,data和priority的意思和CodeCB一样
VM.switchStackAndCall(address, args, stackSize)
在VM中执行并跟踪一个函数,与VM.call不同这个函数创建一个新栈然后把qbdi引擎放到新栈上执行,而目标函数则在原栈上执行,避免目标函数的行为污染qbdi引擎,address直接传NativePointer即可,args传number或者NativePointer都行,stacksize则是分配的栈大小,可以手动设置也可以用默认的
VM.getInstAnalysis(type)
获取当前指令的信息,这个函数在回调中使用,type是下面五个枚举量的掩码
- ANALYSIS_DISASSEMBLY
- ANALYSIS_INSTRUCTION
- ANALYSIS_OPERANDS
- ANALYSIS_SYMBOL
- ANALYSIS_JIT
其中ANALYSIS_SYMBOL运行时基本没正常过,ANALYSIS_JIT一般用不到,ANALYSIS_DISASSEMBLY可以生成指令的汇编,ANALYSIS_INSTRUCTION记录指令的地址之类的信息,ANALYSIS_OPERANDS记录了指令所有参数的信息
VM.getInstMemoryAccess()
获取上一次指令的内存访问信息,记录了访问类型,读写地址,读写值,读写大小
VM.setGPRState(state) VM.getGPRState()
获取和设置VM对象的常规寄存器信息,通常用在执行前和frida同步数据上
GPRState.synchronizeContext(FridaCtx, direction)
用于从FridaCtx(回调里的this.context)中读取上下文信息并写入到GPRState中,direction参数因为从GPR向Frida写入的功能未实现所以并没有什么意义,只能填FRIDA_TO_QBDI
GPRState.getRegister(rid)
根据寄存器名或寄存器id返回目标上下文中的对应寄存器值
InstAnalysis
这个对象是VM.getInstAnalysis返回的对指令的分析,有一下几个属性是比较重要的
- inst.address 指令的地址
- inst.disassembly 反汇编
- inst.operands 一个数组,记录了指令的所有参数信息
- inst.operands[i].regAccess 这个参数的寄存器访问类型,0就是没访问,1是读,2是写,3是读写
- inst.operands[i].regName 如果访问了寄存器则这一项是寄存器名
- inst.operands[i].regCtxIdx 寄存器id,注意到如果访问
eax不会返回rax而是返回eax,但两者对应的寄存器id是一样的,而gprState.getRegister如果以寄存器名为参数只认识rax而不认识eax,使用寄存器id查询则没有这个问题
MemoryAccess
由vm.getInstMemoryAccess返回的记录指令内存访问信息的对象,有以下几个属性比较重要
- memAcc[i].instAddress 同样记录了哪个位置的指令访问了内存
- memAcc[i].type 记录了访问类型,即读,写,和读写
- memAcc[i].accessAddress 访问的内存地址
- memAcc[i].size 访问大小
- memAcc[i].value 读或写的值
简单Trace模板
代码
有了上面这些API,就能搓一个简单的Trace模板了,这里直接贴代码
1 | import {AnalysisType, CallbackPriority, InstPosition, MemoryAccessType, OperandFlag, rword, SyncDirection, VM, VMAction} from './frida-qbdi' |
这里我们先注册指令前和指令后回调分别记录指令执行前后的寄存器信息,然后再注册一个内存读写回调记录内存读写信息,然后做一点简单的格式化,把采集到的信息以相对整齐的格式记录下来,主要是指令地址,寄存器变化和内存变化,这里还可以用frida获取到的二进制文件基址来算出指令的偏移并记录,这样Trace回调的部分就完成了
然后设计Trace触发的部分,这里我们希望其尽可能还原真实运行的状态,所以我们用frida替换原函数,然后在hook触发时先恢复原函数入口点,这一点很重要,不然qbdi会跑进frida的指令里,然后我们直接同步上下文并把原函数hook到的参数传进去,同步寄存器后直接运行,采用switchStackAndCall是因为这个api会让指令在原栈上运行且不用我们自己管理栈
目标测试程序
1 |
|
这里trace _xor这个函数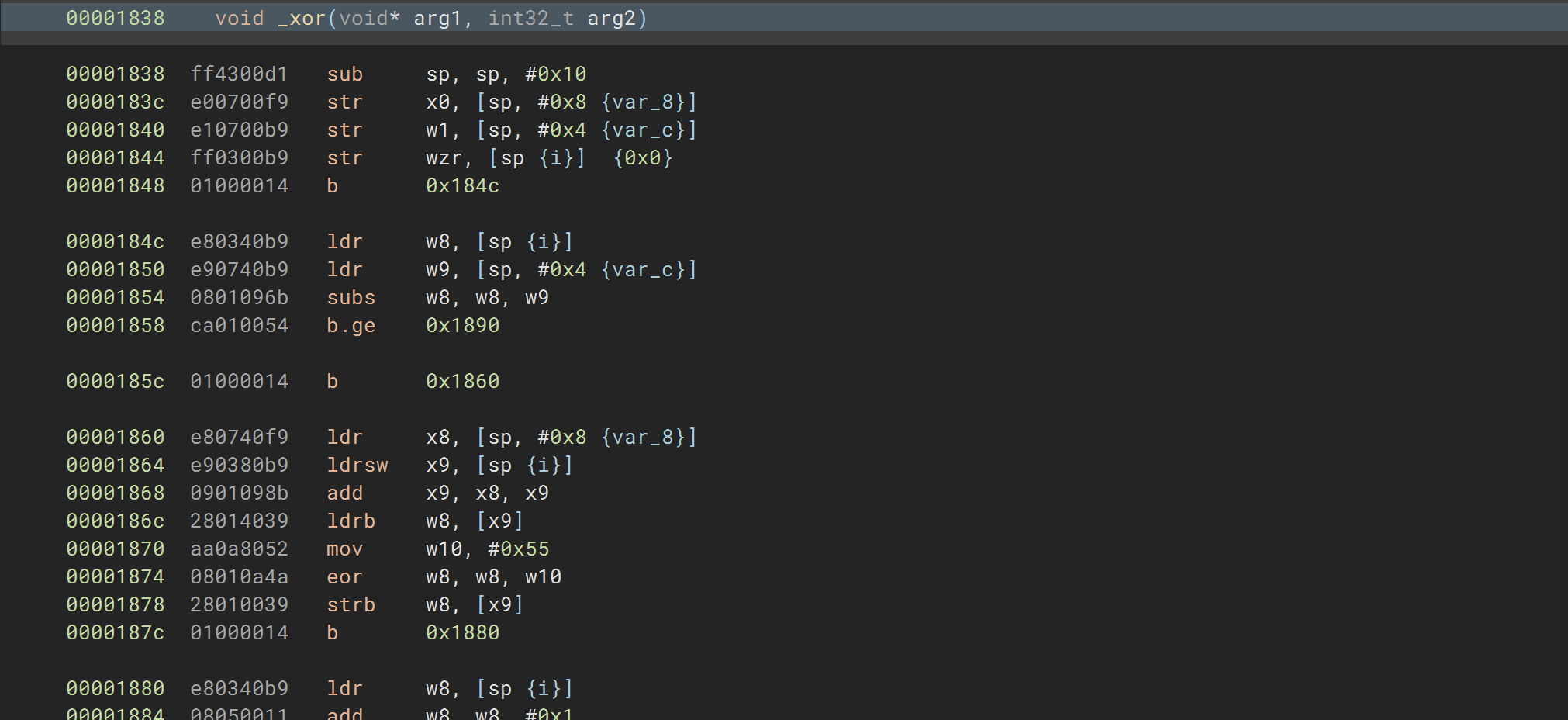
trace日志
最后甚至可以在日志中加点ANSI字符上色,忽略ai做的幽默配色
可以看出来效果还是不错的,配合vscode相同字符串高亮还可以帮忙分析循环节
缺点就是qbdi在x86上还是有不少bug,这个代码的内存读写监视部分在x86上就随机出现内存访问错误,导致内存监视不全,对arm64测试下来倒是没发现问题
stalker别来沾边,我怕qbdi误会