让我看看你的系统调用 - ebpf常见挂载点
基本上所有设备都能用的常见挂载点,目前考虑6.1内核,可惜的是pixel 6 的6.1内核还不支持fentry/fexit
Kprobe
Kprobe是比较常见的附加到内核函数的方法,kprobe/kretprobe分别负责在进入前和返回前hook内核函数
用法是使用SEC(kprobe/name),直接使用内核函数的签名即可,比如SEC(kprobe/kernel_clone),这个签名可以在/proc/kallsym中获取
获取调用参数有两种方案,最基础的方法是使用struct pt_regs *ctx作为参数,这个ctx结构体是具有架构依赖的,然后使用PT_REGS_PARM*(ctx)宏读取参数,arm64架构中这个可以填1~8
1 |
|
这就是一个比较简单的探测kernel_clone这个函数的kprobe探针,使用PT_REGS_PARM1读取第一个参数(每个具体参数要查阅内核源代码中的定义),使用bpf_probe_read_kernel读取这个指针指向的参数列表结构体(直接解引用会被检查器拒绝加载,因为这是不安全的行为),然后根据flag这个掩码参数简单区分下进程和线程,通过bpf_get_current_pid_tgid获取调用clone的进程pid,使用printk输出到trace_pipe中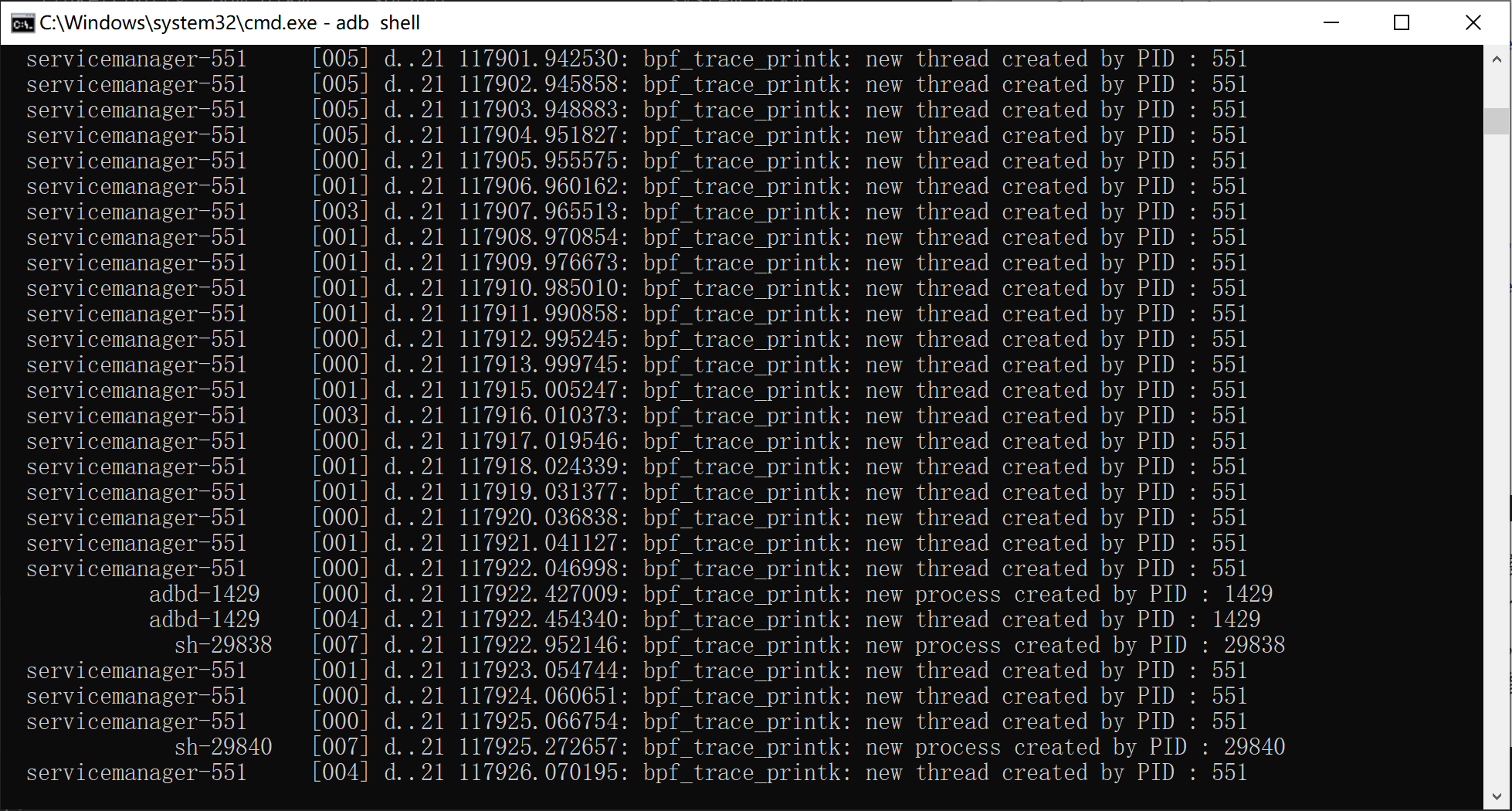
可以看到捕捉到了adb服务的活动,和新创建的shell的活动
除了直接声明函数还可以使用BPF_KPROBE这个宏,上述的代码可以写成如下等价形式
1 |
|
这个宏的第一个参数是声明的函数名,之后接受最多五个参数,作为前5个传参寄存器中读取的参数(PT_REGS_PARM1~5),写起来会比第一种写法简洁一点,基本所有探针类型都有类似的宏
以及对于这些宏,触发探针时的上下文环境会被以*ctx保存,可以通过ctx访问上下文环境,所以不要在函数中再次使用ctx作为变量名
另外还有一种libbpf提供的语法糖ksyscall,因为linux syscall函数的命名通常遵循一定标准,ksyscall可以根据部分提供的函数名自动选择对应的函数附加(比如ksyscall/openat就会选择一种openat的实现),不过由于syscall通常由多种实现所以这种方法很容易漏掉调用,所以其实不大好用
Uprobe
Uprobe是用来hook用户态函数的探针,原理是把目标地址的指令替换成int3(其他架构上就是对应的中断指令)跳到内核态执行hook逻辑(类似条件断点脚本),但是和调试器相比隐蔽性更强,这篇文章中总结了一些Uprobe的对抗手段https://www.cnxct.com/defeating-ebpf-uprobe-monitoring/
总结一下的话就是一下几点
- 扫描中断指令
- 在maps中扫描[uprobe]内存段(用于储存被中断替换的指令)
- 将保护目标.text段的权限设置为
VM_WRITE使得uprobe的valid_vma函数校验不通过(前提是要对目标二进制文件有修改权限)
Uprobe可以做到任意位置插入,因为只有一条断点指令所以也不会出现短指令问题(说的就是你frida),监测性能也会高很多,下面是几种UPROBE探针的示例
完整demo
1 | // bpf_test.bpf.c |
1 | // bpf_test_loader.cpp |
1 | // 测试程序 test.cpp |
关于hook地址获取
不是很清楚linux内核的开发者是怎么想的,uprobe接受的偏移是目标地址相对其所在段起点的偏移再加上所在段的偏移值,而不是相对其所在二进制文件起点的偏移,通常就是理解为相对.text段起点的偏移加上maps中读取到的text段的偏移值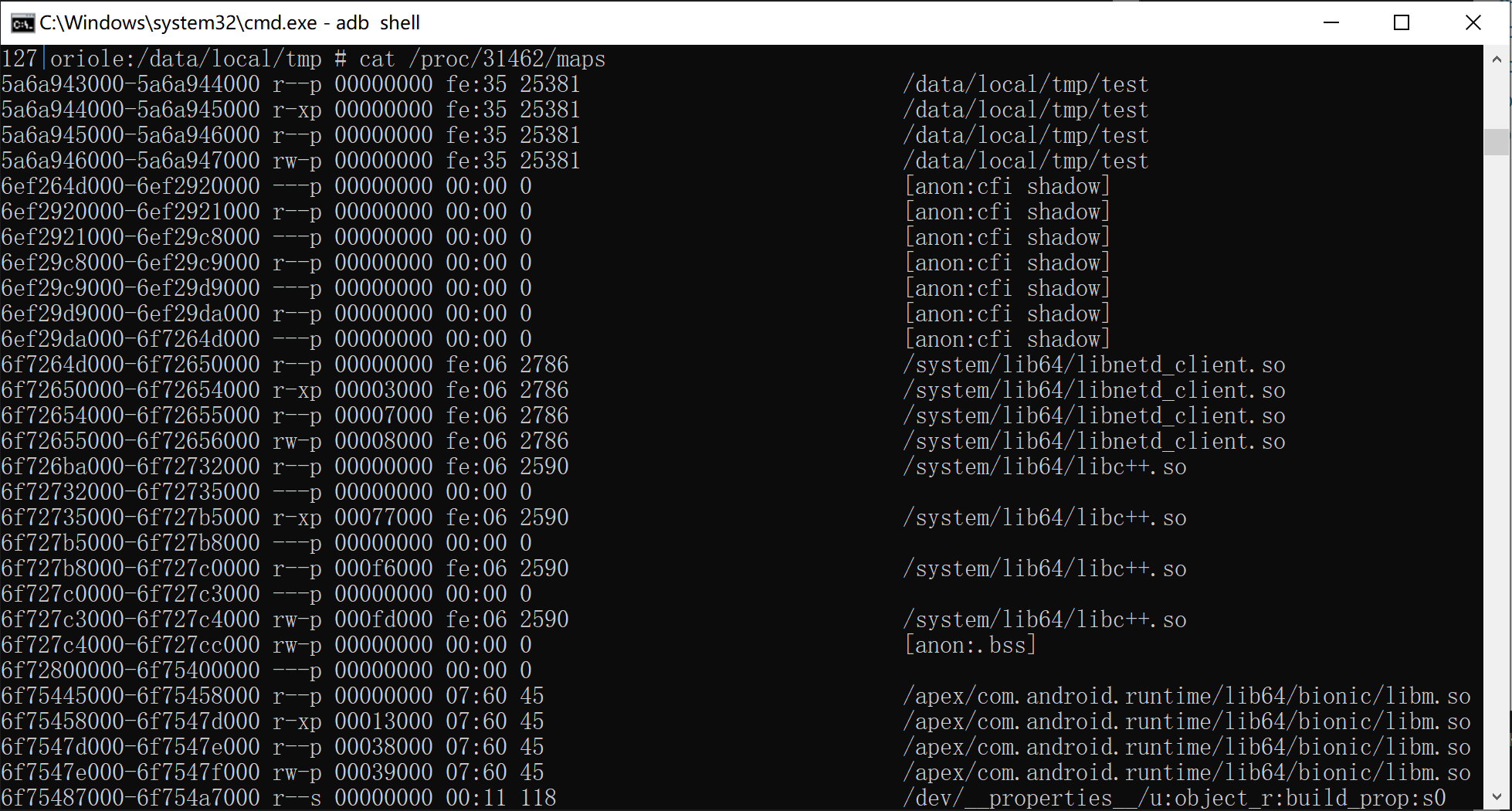
如下图所示,权限掩码带x的段就是可执行的段,我们在ida里看到的是这样的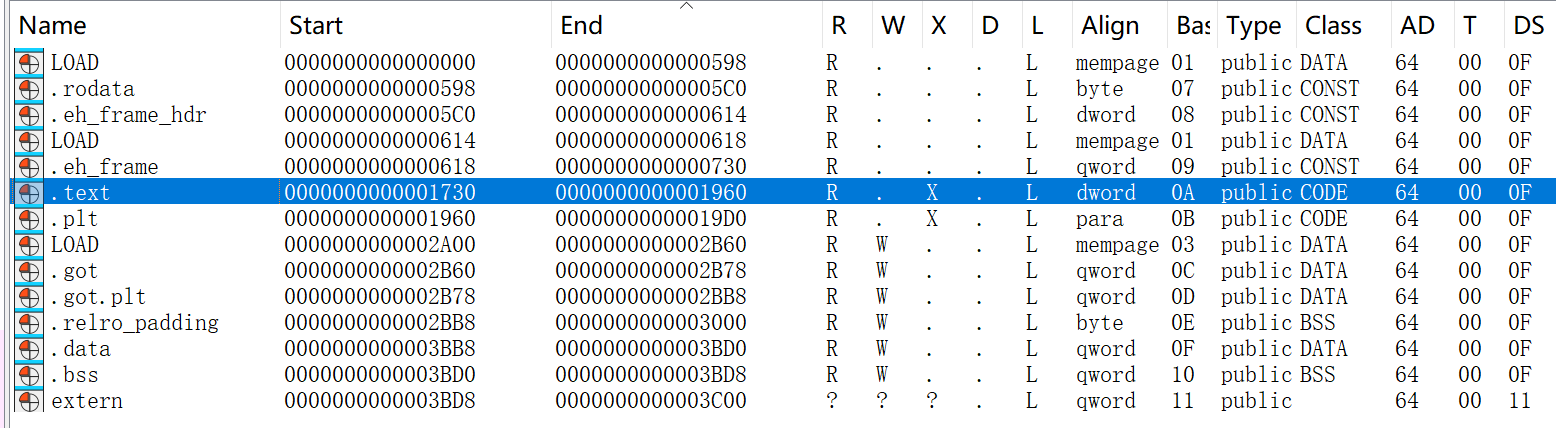
这里.plt和.text在运行时被合并了,不过这个不重要,我们的目标函数如下图所示,显然是在.text段里的,然后0x1830这个地址,是base为0的情况下,相对二进制文件起始位置的偏移,也就是我们在frida等框架中使用的函数地址,在uprobe中不能直接传这个地址,在运行时,前面长度总计0x730的其他段会因为对齐变为长0x1000,然后经过计算,实际上要传入的地址应该是0x830(因为读取到的段偏移值为00000),也就是 目标实际地址(相对文件起点的偏移+基址)-所在段的基地址+所在段的偏移值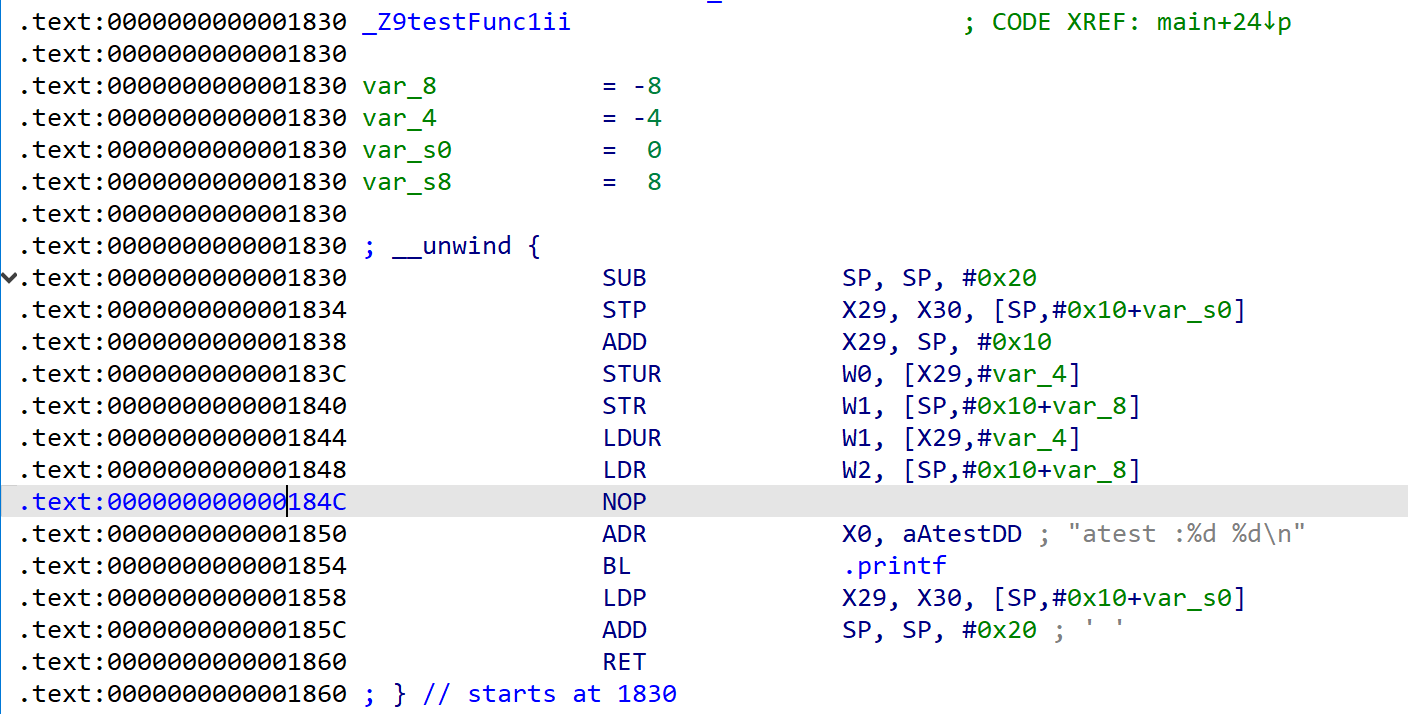
显然这一坨不可能每次手算然后硬编码,我们用一个函数把反编译工具中获取的偏移值转换为uprobe认可的偏移值
1 | size_t getFunctionOffsetReal(const char *soName, size_t staticOffset, int pid) { |
hookTestFunc1
1 | // probe |
uprobe也可以使用BPF_UPROBE宏,事实上这个宏就是BPF_KPROBE的别名(ebpf将uprobe和kprobe视为等价的)
然后我们采用手动链接的方式(自动链接不能指定地址),注意这里hook可执行文件的话,我们的二进制文件要选/proc/pid/exe,这是对源文件的一个符号链接(快捷方式),这样我们就不用自己输入路径了,我们指定pid只hook测试文件,并设置uretprobe为false
hookTestFunc2
1 | int testFunc2(int *a, int *b) { return *a + *b; } // 突然发现test2和test1一样,遂修改 |
1 | SEC("uprobe") |
如果要从用户空间读内存,则需要使用bpf_probe_read_user,原因和上文的bpf_probe_read_kernel同理
hookTestFunc3
1 | SEC("uretprobe") |
uretprobe直接在宏里定义返回值即可,libbpf会根据 调用约定 自动解析返回值对应的寄存器并读取到ret里
这里就要设置uretprobe为true了,注意uretprobe只能设置在函数开头,然后会把函数return的地址替换成 蹦床 的地址(用于执行hook逻辑) 并保存原return地址,在执行完hook逻辑后跳回原执行流,因此uretprobe只能由return触发,灵活性要较差
insideFuncHook
1 | SEC("uprobe") |
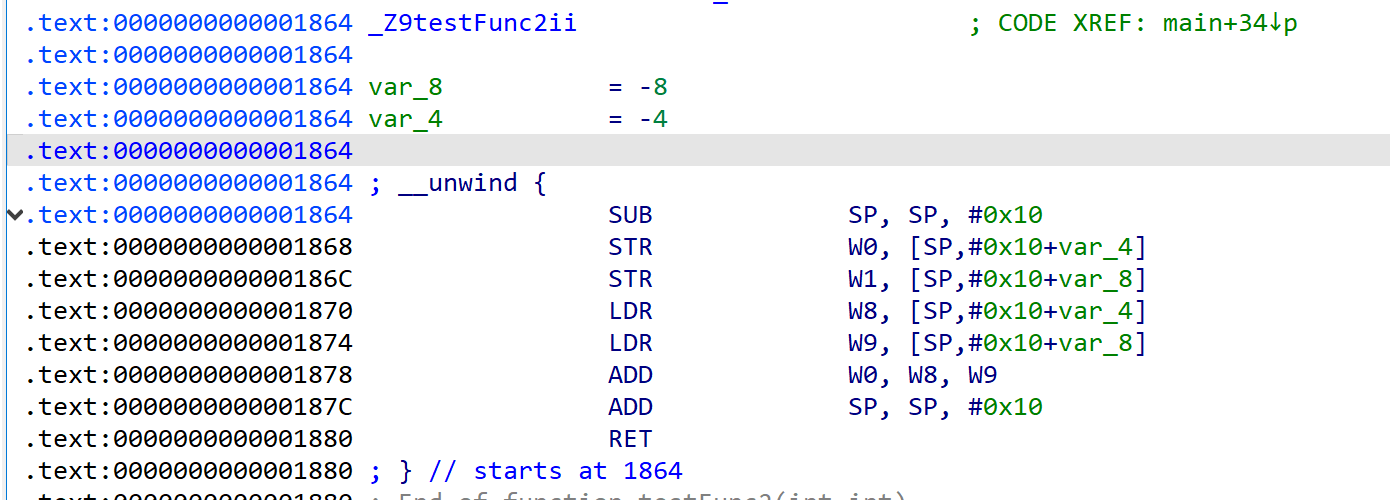
这里我们想读w8和w9寄存器的值,直接在对应位置hook然后读取ctx里regs[8]和regs[9]即可
modifyArgProbe
1 | SEC("uprobe") |
注意到对uprobe来说寄存器是只读的,所以如果参数通过寄存器传递,我们没办法直接替换参数,只能通过这种修改栈变量的方式简介修改参数,操作性比较差
运行情况
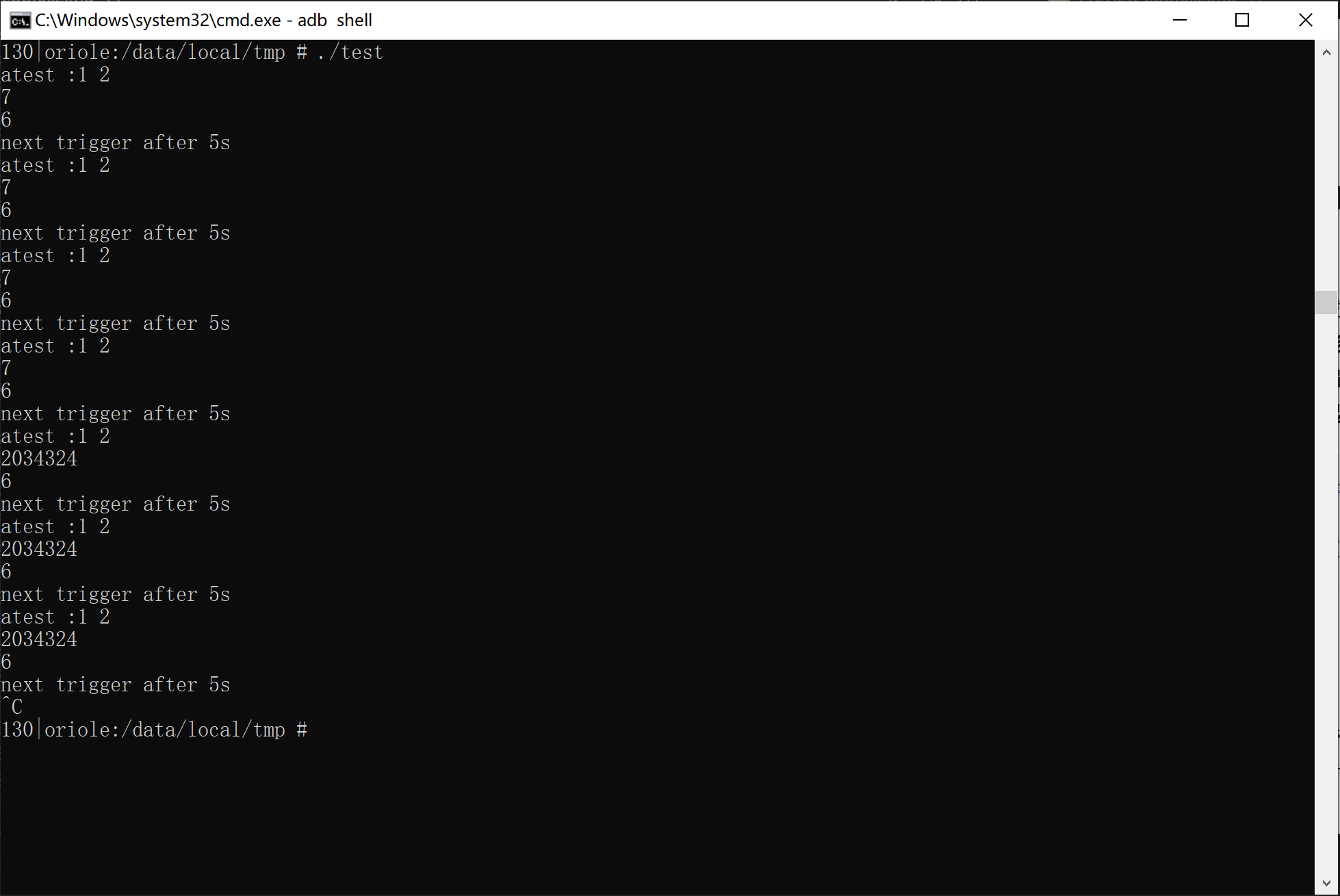
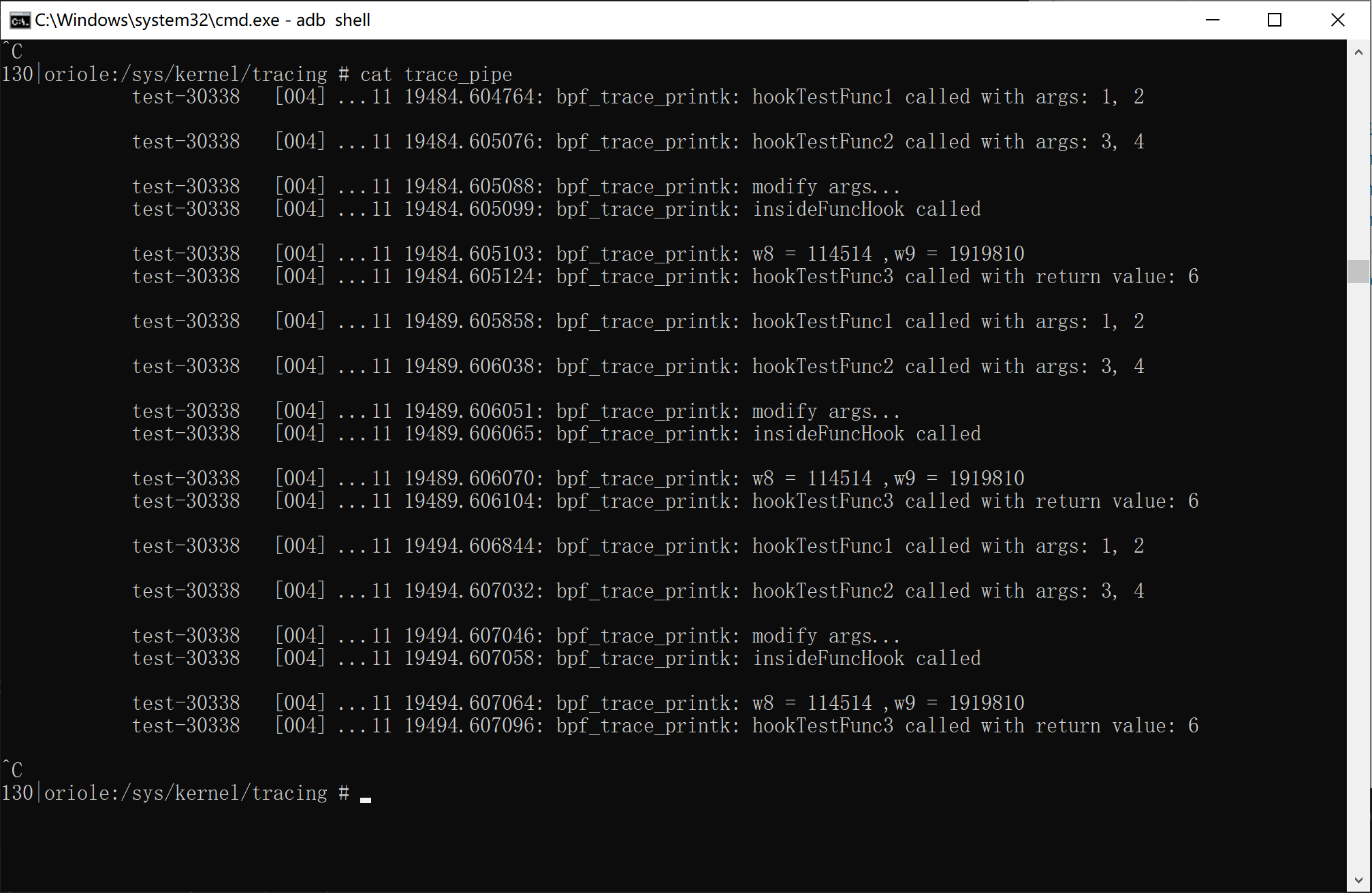
几点不足
uprobe最大的问题是没法修改寄存器,导致其很难影响用户空间的行为,同时uretprobe虽然可以通过bpf_override_return替换返回值,但前提是内核开启了CONFIG_KPROBE_OVERRIDE,而pixel 6的内核是未开启的,必须得重编译,如此下来用uprobe做拦截操作就非常不优雅,stackplz的解决方案是联动frida使用ipc调用来干涉用户空间,个人也认为联动frida或者集成ptrace做修改操作会比较好,而且集成ptrace可以在需要修改时才附加ptrace,可以同时发挥uprobe的隐蔽性和ptrace的修改能力
Tracepoint
tracepoint
Tracepoint其实没啥好说的,就是内核预埋的一些检测点,内核支持的Tracepoint全部在/sys/kernel/tracing/events目录下了,对应的区段名为SEC(tp/catalog/name),比如sys_enter对应的就是SEC(tp/raw_syscalls/sys_enter),对应事件目录下的format文件描述了这个检测点获取的参数列表
对逆向分析而言我们主要关注raw_syscalls,里面的sys_enter和sys_exit是所有libc函数调用syscall时都到经过的
1 | oriole:/sys/kernel/tracing # cat events/raw_syscalls/sys_enter/format |
1 | name: sys_exit |
这里重点关注id,args,ret即可,这里其实就是svc指令
1 |
|
1 | // SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) |
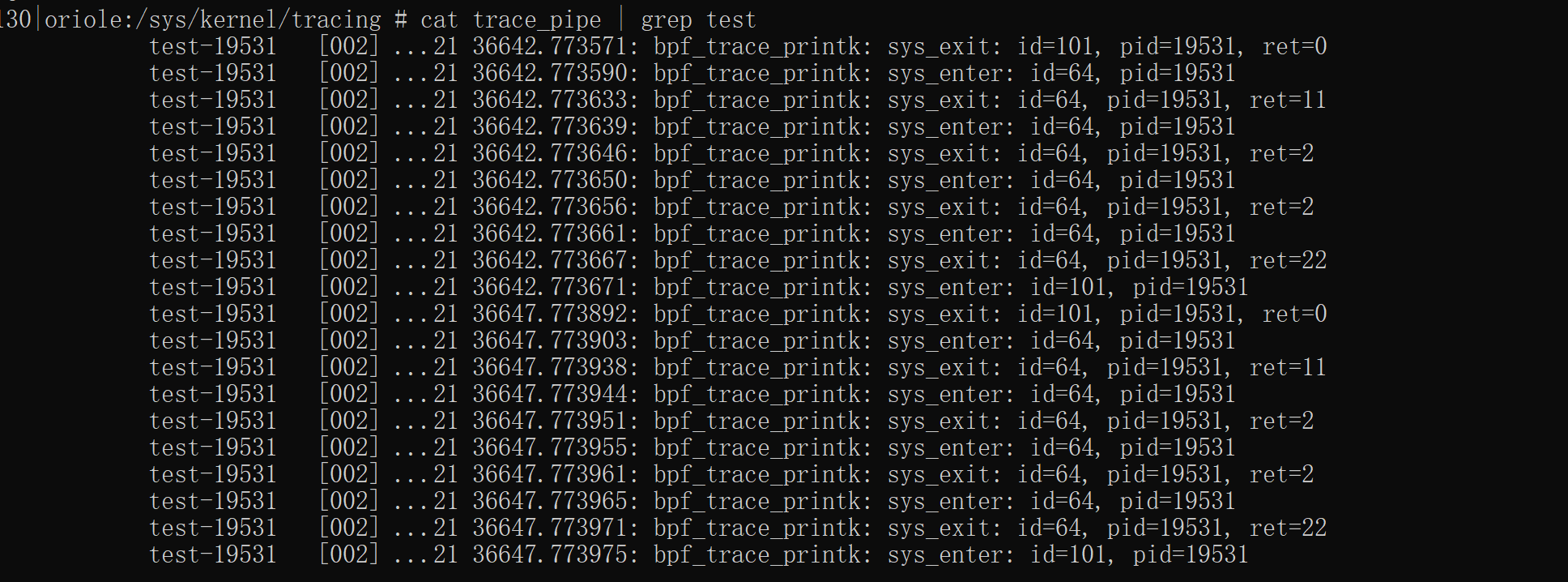
之前的格式表中的前8个字节的common_字段是不能直接读的,要用bpf_read_kernel或BPF_CORE_READ读,下面的字段都是可以直接读取的
运行可以发现调用了101,64两个调用号,查表发现是nanosleep , write,符合我们的预期,之后根据不同调用号写case解析数据就可以实现stackplz相同的监控功能
btf_raw_tracepoint
btf_raw_tracepoint是相对tracepoint更加原始的检测点,使用的内存段是SEC(tp_btf/name),btf_raw_tracepoint和raw_tracepoint类似,访问的都是调用的原始参数,即直接返回调用号和寄存器信息pt_regs,而不是类似tracepoint的返回整理过的参数结构体,好处是通过raw_tracepoint可以获取全部的寄存器信息而不只是前6个,btf_的意思是使用btf类型增强兼容性,在应用中通常使用btf_raw_tracepoint
1 |
|
上述就是一个简单的监测write的demo,其中ctx[0]是上下文信息(寄存器),ctx[1]是调用号,具体的参数需要自己查syscall表,arm64的write的话就是x0是fd,x1是buf,x2是len;
Syscall
如果内核开启了CONFIG_FTRACE_SYSCALLS的话就可以使用,使用方法是SEC(tp/syscall/name)宏,大部分手机的原厂镜像应该是不支持的
fentry/fexit
如果内核支持fentry可以使用,和kprobe语法类似,SEC(fentry/name),与kprobe不同的是fentry/fexit对每个内核函数提供了参数结构体,可以直接使用Args->fieldname的方法访问参数
pre — next
让我看看你的系统调用 - ebpf常见挂载点