栈数据的采集与使用 - ebpf番外篇之解析perf_event
在研究stackplz的代码时发现其是用perf_event_open进行栈数据的采集,并且因为libbpf的perf_event_open并没有带上PERF_SAMPLE_STACK_USER标记所以还要修改libbpf代码,感觉总体实现并不是很好并且perf_buffer性能也不咋地,所以研究有无其他获取栈数据的方式
perf_event_open
采集项开关
根据linux syscall手册,perf_event返回的数据通过attr结构体中的一系列掩码决定,其中开启采集栈数据的就是PERF_SAMPLE_STACK_USER
stackplz的解决方案
stackplz是在libbpf调用perf_event_open时手动为掩码添加新采集项
perf_event_open如何获取栈数据
既然bpf程序对用户内存有读取权限,不如考虑有没有直接把目标栈内存整个读下来的方案,先来看看perf_event_open是如何获取栈数据的

可以看到这里只是注册了perf事件,触发事件的回调在perf_event_output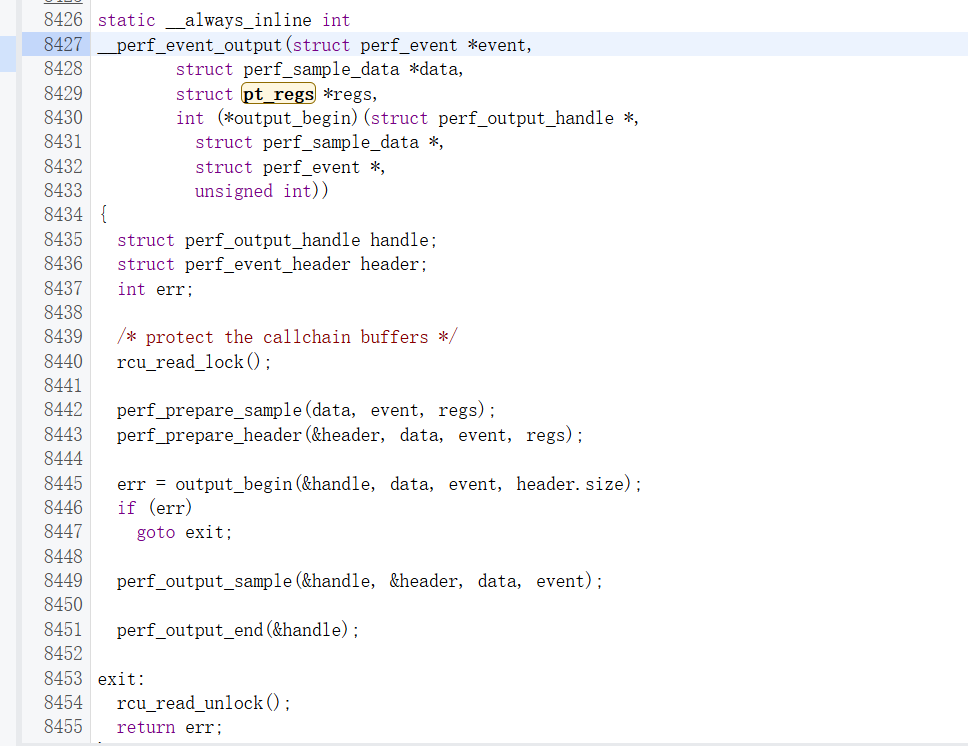
这里关键的函数是perf_output_sample,负责把数据拷贝到目标缓冲区里
根据对应开关我们找到perf_output_sample_ustack这个函数
检查一下这个stack_user_size是怎么初始化的
可以跟到perf_prepare_sample这个函数中,这样和前面的逻辑是对的上的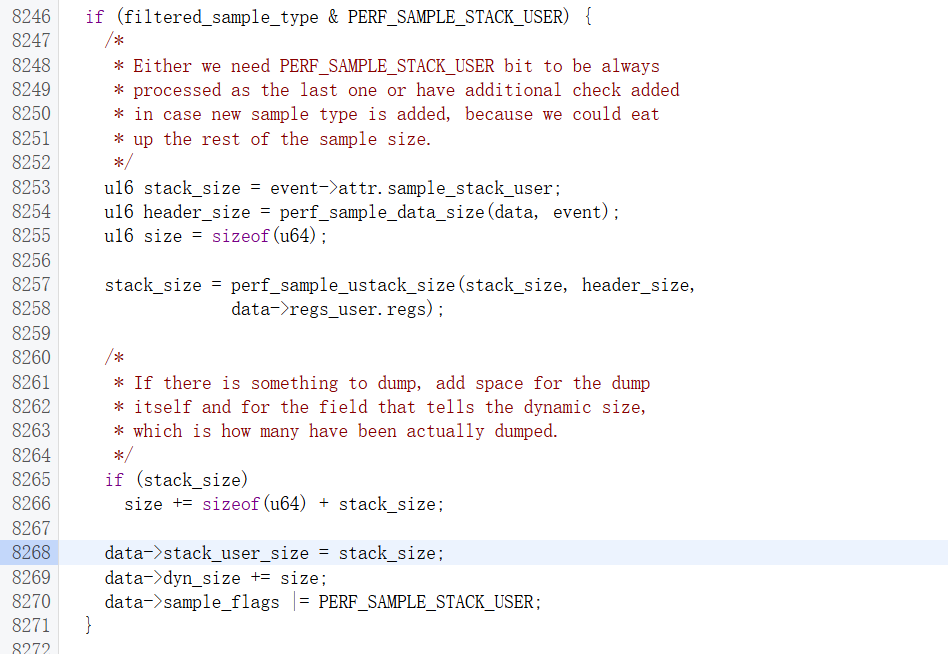
这里通过perf_sample_ustack_size获取栈大小,可以看到用户传递的attr.stack_size只是参考,真正dump的大小要根据perf_sample_ustack_size得到
这里进一步通过perf_ustack_task_size计算栈大小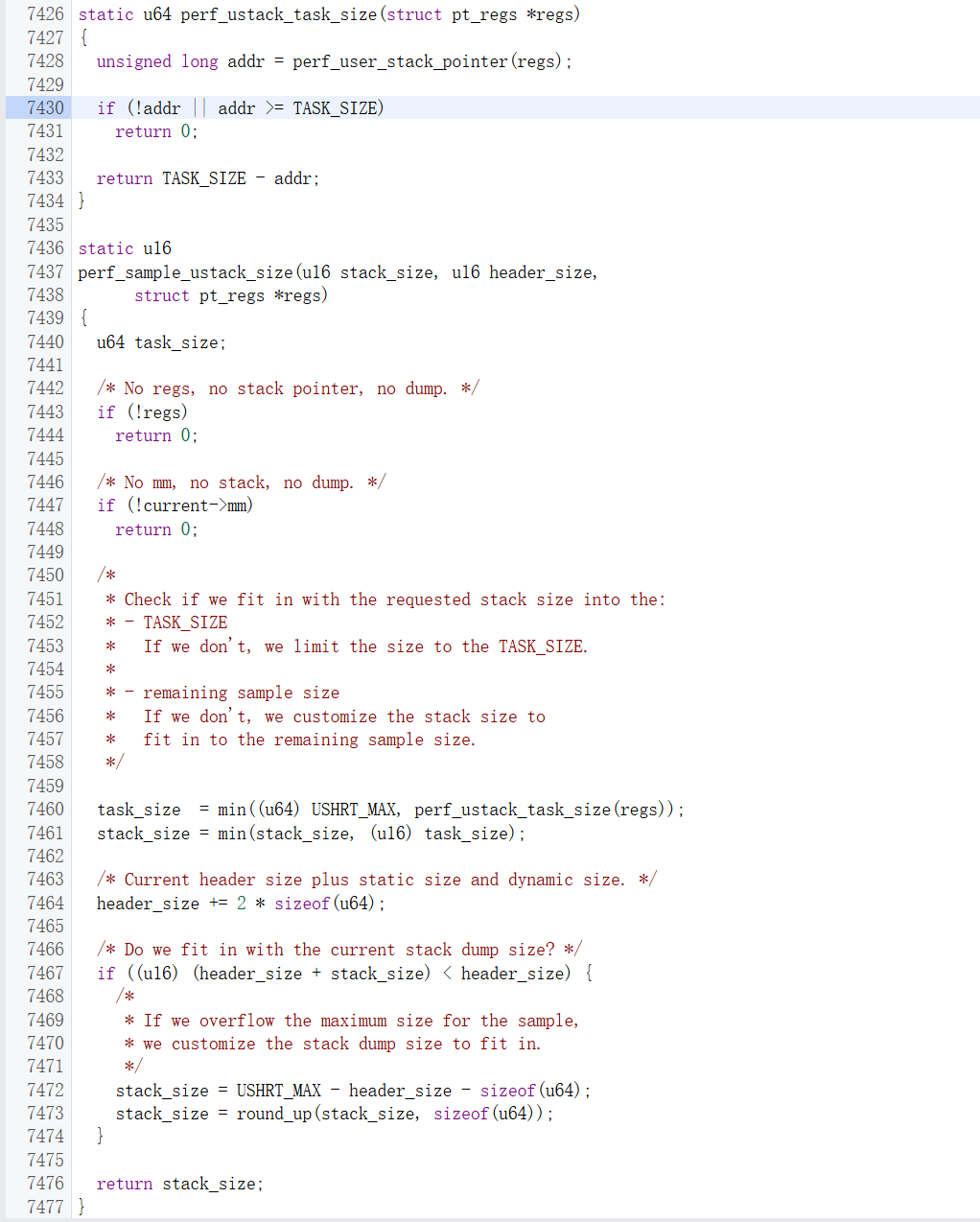
这里perf_ustack_task_size是计算栈不从用户地址空间溢出的前提下的最大大小,然后和用户指定的大小取min,再和perf事件一次最多采样65535字节的限制取min,最后算出最多能采多少数据
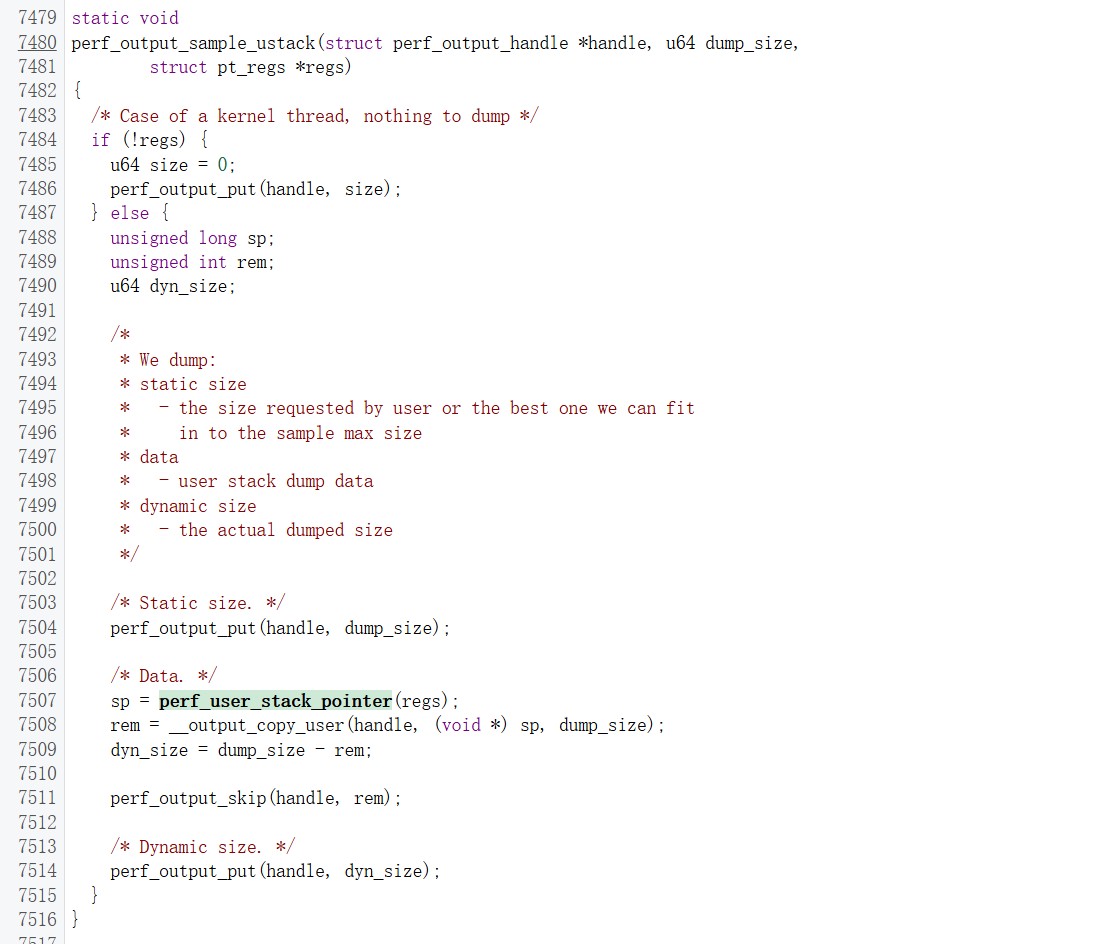
这里先是提交了dump_size作为预期dump的大小,再通过__output_copy_user从sp开始拷贝栈数据,最后提交dyn_size作为实际拷贝成功的大小
这里主要关注这个dyn_size是怎么计算出来的,因为unwindstack需要这个数据
这个__output_copy_user宏最后可以跟到__copy_from_user_inatomic这个函数
最后从raw_copy_from_user继续跟,就是内联汇编的代码了,这里真正执行了拷贝操作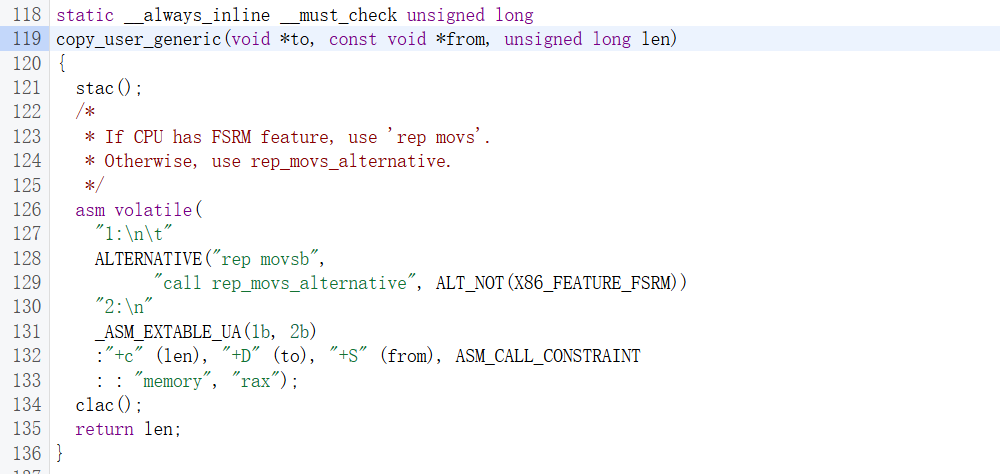
这里只找到了x86的代码,但估计arm的也是差不多的rep movsb指令是字符串复制指令,其行为是
- 从
rsi读一个字节并写入rdi - 递增
rsi和rdi - 递减
rcx - 循环直到
rcx变为0
_ASM_EXTABLE_UA(1b,2b)是注册了一个异常处理事件,在内核访问用户内存发生异常时跳到2:处继续执行而不是崩溃
最后是把c变量绑定到寄存器,这里是把len绑定到rcx,把to绑定到rdi,把from绑定到rsi,其中to和from都只是储存,而len则是更新并储存,可以理解为len的值始终和rcx相同
可以发现这里return的话返回的值就是还剩多少没拷贝(比如发生了页错误),和前面的stack_size相减算出了实际的dyn_size
bpf_probe_read_user
既然本质是从sp开始读数据,那没道理说直接拿bpf_probe_read_user读就不行,一个比较直接的思路是直接拿到stack段的基地址,然后和sp减一下算出来一段合法的区间,直接去读这段区间的内存,唯一的缺点是和内联汇编相比遇到错误整个读取都会失败
如何确定栈基址
目前的思路是通过解析maps文件获取栈基址,属于栈内存的区段会有stack标记,具体规则是单独的[stack]属于主线程,[stack:xxxxx]是对应的子线程内存,[stack:main]不确定是什么东西,但查看了多个进程都发现这个段只有4kb(一个页),估计不是很重要
效果
采用了这个方案后在部分场景确实能正确获取栈数据,但是在追踪某社交平台app时还是出现了回溯截断现象,推测是在复杂场景中获取的内存数据有错误(毕竟是野路子,没错误处理,还直接从sp开始硬读),也可能是大型app的回溯本身就需要很多其他数据,后续如果想解析vdex符号还是直接上remote_unwinder吧,bpf侧只需要发送中断信号和读取寄存器数据就好了
栈数据的采集与使用 - ebpf番外篇之解析perf_event